- Products
Network & SASE IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SASE SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloud Cloud Network Security CloudMates General CloudGuard - WAF Talking Cloud Podcast Weekly ReportsSecurity Operations Events External Risk Management Incident Response Infinity AI Infinity Portal NDR Playblocks SOC XDR/XPR Threat Exposure Management
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
CheckMates Fest 2026
Join the Celebration!
AI Security Masters
E1: How AI is Reshaping Our World
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
Watch NowOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
Maestro Madness
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Management
- :
- High CPU usage on management server [r81.10]
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
High CPU usage on management server [r81.10]
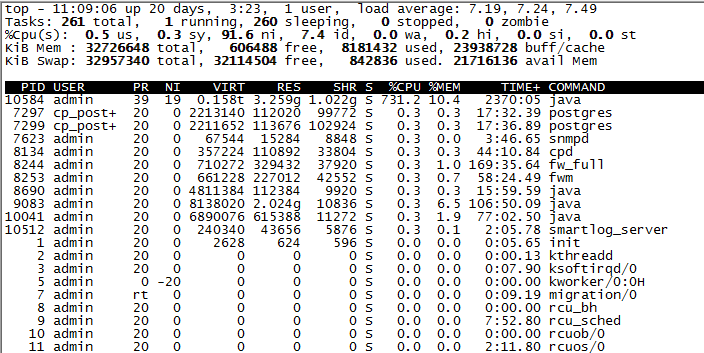
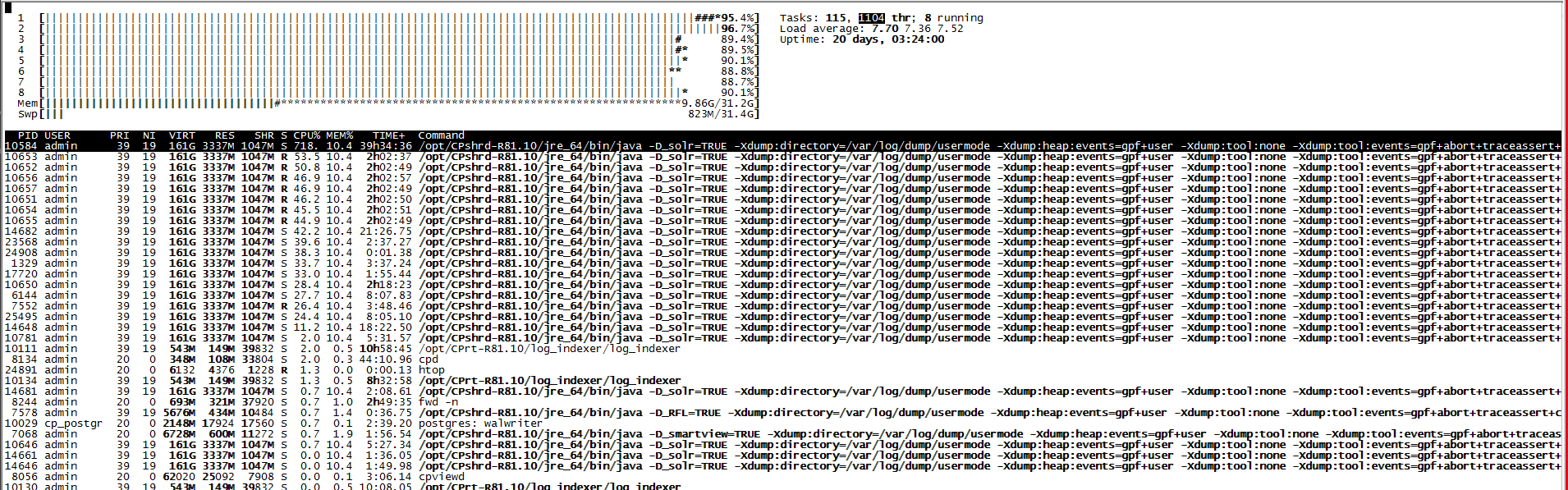
We have upgraded from r80.40 to r81.10 some time ago. In the beginning the 100% CPU usage on the management server was expected as it was reformatting the logs for r81.10. Unfortunately we have been getting sporadic spikes in cpu usage causing the recent traffic not to be shown in the console.
Our Situation:
2x Open server in HA (active-standby) On premise
2x Azure Checkpoint appliances in HA (active-standby)
1x Security management server 8 vcpu 32 Gb (VmWare)
We have a VPN tunnel between azure and on-premise.

top and htop are attached.
sincerely,
Bram
Labels
- Labels:
-
Logging
-
Monitoring
-
SmartEvent
{kind=link}
{kind=link}
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you recently upgraded, make sure that its not “still reindexing your logs” (after upgrade to r81x we reindex all the logs)
13 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The nice (NI) value shown in top for the CPU-heavy java processes is 19, which means they are set for minimum CPU priority. These are going to be your log_indexder and SOLR processes, which will get kicked off the CPU immediately if some other process needs to use it. There have been several other threads about this and it is expected behavior, if you are having issues with logs not showing up in a timely fashion there could be contention for the hard drive, although your waiting for I/O (wa) is showing as zero.
Gaia 4.18 (R82) Immersion Tips, Tricks, & Best Practices Video Course
Now Available at https://shadowpeak.com/gaia4-18-immersion-course
Now Available at https://shadowpeak.com/gaia4-18-immersion-course
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
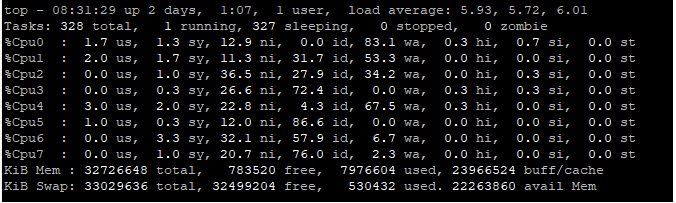
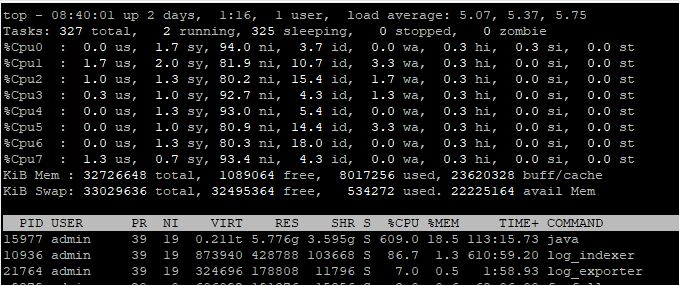
did you solve this issue? I currently have two environments with the same symptoms as you with high CPU ussage(after mgmt upgrade to R81.10 CPU is at 90%) Before the upgrade it was 20-30%. In one environment, I observed that the issue was caused by log_exporter, but after a while (2 days) the CPU levels were OK. For some reason, after the upgrade, I see a lot of wa (wait) when running the "top" command on the mgmt server. Like Timothy suggested my first culprit was disk. But after checking the actual disk r/w I can see that there are spikes up to 150M but this should still be OK. Mem is OK, NICs are OK so I don't know what is causing CPU waits in such a number? At the top we have java process with 600%, followed by indexer and exporter at 100% All of them have NI value of 19. What I did noticed is that when wa kicks in java process drops fromm 600 to 100. Then it rises again until there are wa's again...
P.S. before the upgrade everything was working OK, so something changed. Two different environments.
Br J
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you recently upgraded, make sure that its not “still reindexing your logs” (after upgrade to r81x we reindex all the logs)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Dorit, nice to hear from you. It seems you were right - both systems are now running OK. After your suggestion I did some further investigation and noticed that all the environments that had manually added custom value of"days_to_index (value)" in $INDEXERDIR/log_indexer_custom_settings.conf, prior to upgrade had high CPU issue. And this files survives and upgrade. As stated in https://community.checkpoint.com/t5/Management/Cannot-view-previous-logs-after-upgrade-to-R81/td-p/1... R81 should only re-index logs for 24h unless triggered manually - but that is something a reboot does 🙂
What was weird and made me look away from indexing is that the process that was consuming CPU was java, not log_indexer as in previous versions when re-indexing.
Thank you for your response!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@cir007 JAVA process that was working hard during reindexing is actually SOLR daemon (you can see it in top -c).
The default value of Days to Index is 24 hours, I don't know what was the reason to change it prior to upgrade, and usually it is not necessary, but specifically in upgrades from R80.x to R81/R81.x, users might change this value to a longer time. In R81 we upgraded the SOLR indexing engine, and the new engine cannot read from indexes that were created prior the upgrade.
Now after reindex is completed, I'm sure you notice much faster log queries and reports.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
a OK I can see it now. The reason why this value is/was changed is because of Smarevent reports. At some time the customer wanted to have the ability to create Smart-event reports for 90/180 days. To achieve that disk space was added to the mgmt and logs were imported back to SE and re-index so that the customer could could do reports for more than 14 days.
Unfortunately that did not played out well, after the upgrade to R81 I've noticed that re-index for old logs is not done properly as some chunks of indexed logs are randomly missing. I've deleted the new index files and ran another re-index but the result was almost the same in two environments where the need for Smart-event history is "required" I've contacted TAC on this issue.
Thank you for replay.
Br J
Yes I do have to say, new reports and queries does feel faster, kudos for that 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see. please share with me the SR privately, I will monitor the case with TAC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi jb1!
Have you got any updates on this case?
I'm having a similar problem and I'd like to know if you could share any info that could help.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Fernando!
If you are talking about the high CPU than the issue was SOLR daemon re-indexing old files. If you are talking about the problem where some logs were not indexed, then I just, received word from TAC yesterday actually, saying that they found a problem and portfix is available. They also mentioned that this fix will be implement in the next JHF, that will be out in a couple of weeks. In this environment. Hope this helps.
Br J
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi jb1!
Thanks for your reply.
Already solved mine; SMS was stuck trying to reindex log files.
As it was a VMWare machine, I was able to reinstall the SMS entirely and that solved the problem somehow.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Fernando,
a drastic move 🙂 were any changes made in the $INDEXERDIR/log_indexer_custom_settings.conf? ,specifically with parameter days_to_index
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
How can we assure that re-indexing is not happening.
WR,
Shashidhar
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
"top -c" look for opt/CPrt-R81.10/log_indexer/log_indexer
The CPU usage for this will be close to 100%
17401 admin 39 19 998408 390944 9488 S 14.9 0.6 2162:40 /opt/CPrt-R81.10/log_indexer/log_indexer
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 22 | |
| 13 | |
| 9 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 | |
| 4 |
Upcoming Events
Thu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 12 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 3: Exposing AI Vulnerabilities: CP<R> Latest Security FindingsThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2025 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter