OK sorry to come in late on this thread. After looking at your s7pac output and other screenshots:
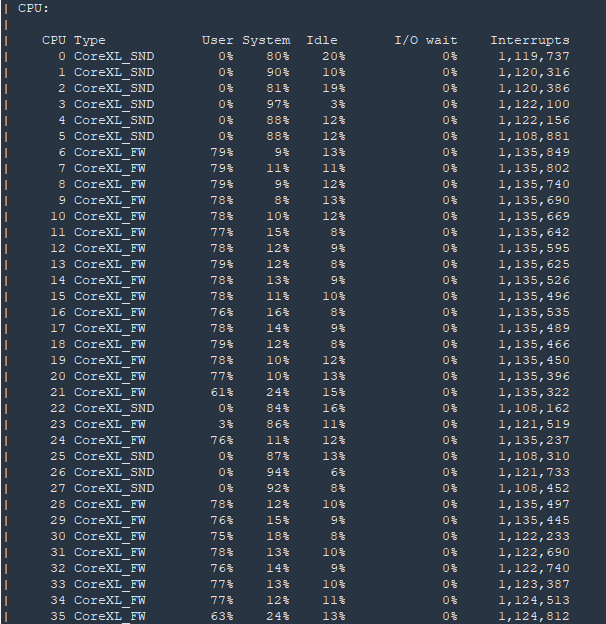
1) Looks like dynamic balancing/split has you in a 28/44 split on your 72-core firewall which is to be expected with only the FW blade active. However one interesting side effect of this is that there are 60 firewall instances/workers, but only 44 cores available for them. So the firewall instances are doubling and tripling up on certain cores, presumably for the duration of their existing connections to decay and the firewall instance to be eventually de-allocated.
2) The high CPU on your firewall workers/instances is almost certainly caused by the very high number of rulebase lookups occuring on your firewall instances in the F2F path (and possibly exacerbated by the associated generation of logs), because the scanners are launching new accepted connections at a very high rate. The first packet of every new connection must be handled by a worker, whether the connection is matched to a SecureXL Accept template (less likely) or has to perform a full rulebase lookup in F2F (more likely). Assuming the scanners are hitting lots of diverse destination IP addresses, very few accept templates will be formed and you will be stuck with the full overhead of F2F rule base lookups for each new connection.
3) fast_accel or disabling the IPS blade will not help this situation, as those features only specify what to do after that first packet has matched a rule or template on a worker, which would be to offload subsequent packets to the SecureXL accelerated path (fast_accel), or disable IPS inspection of the subsequent data stream inside the connection which will happen anyway with fast_accel active.
So trying to improve this situation will depend on your mutually-exclusive goal:
Goal: Allow scans to run as fast and accurate as possible, all other traffic be damned
In your firewall/network policy add a rule as close to the top as possible matching the source IP addresses of the scanning systems with an action of Accept and a Track of None. This would have made a huge difference in R77.30 and earlier, but in R80.10+ with the introduction of Column-based matching I'm not sure how much this will help (if at all) but it is worth a try. If your scanning traffic is currently being accepted after rule 1898 where it is ineligible for templating this change will definitely help, perhaps a lot. The savings in logging overhead may improve the CPU issue on the workers as well, also make sure Accounting is not enabled for this rule.
Ideally if you could somehow manually add broad-ranging SecureXL Accept templates for these scanning systems that would be great, but that is not possible as far as I know.
Goal: Limit the impact of scans on firewall CPU to prefer non-scanning traffic, with the side effect of some (or a lot of) scan traffic getting lost/throttled
Establish new connection quotas that will be enforced directly by SecureXL with no firewall worker involvement via the fwaccel dos rate command: sk112454: How to configure Rate Limiting rules for DoS Mitigation (R80.20 and higher).
I'll give this situation some more thought, but this is the best I can come up with for now.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization


{kind=link}
{kind=link}