- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
The industry's first AI Network Firewall
Securing AI traffic, everywhere
On-Premises SD-WAN Management
Watch Here AI Security Masters E8:
Claude Mythos: New Era in Cyber Security
CheckMates Go:
No Attack Required
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- General Topics
- :
- Re: Check Point for Beginners - Typical Config Mis...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Check Point for Beginners - Typical Config Mistakes
I see here in the forum in the last months several articles, in which typical configuration mistakes are written. Let us write an article in which all users describe their typical configuration mistakes with solutions.

Article:
Danny Jung - Check Point configuration mistakes - Top 10
Victor MR - Top human fails to avoid
...
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
33 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Heiko,
Not necessarily a config error but part of the config process.
Using "Get Interfaces with Topology" if a topology had already been defined and you just want to add an interface.
Regards
Mark
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Mark,
Actually once you check the option get interfaces - it will add the new interface you want.
In the past- there was an issue with reseting antispoofing setting and this also was solved.
see please sk136372.
Could you please elaborate and answer, whether it is satisfy you?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My classic, which I see again and again at customer firewalls. The TCP and UDP timers are set globally to the maximum values. This will fill the state table very fast.
Default settings:
TCP session timeout: 3600 sec.
UDP virtual session timeout: 40 sec.
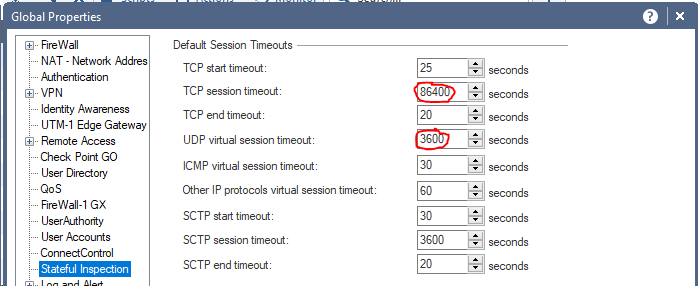
Solution:
Set the values for a single service if necessary.
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have often seen that the value "Limit the maximum concurrent connections" is set to very high values. After installing the policy there can be problems with resources because no memory is available for the connection table.
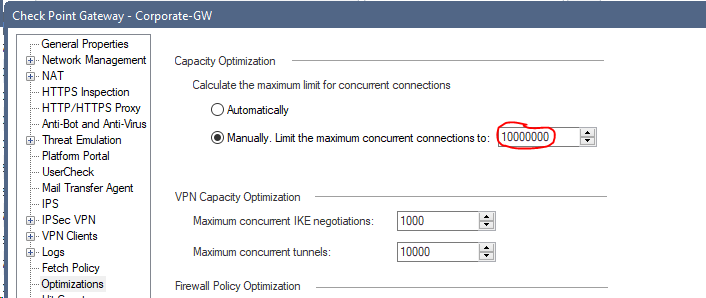
Solution:
Sets the value to automatic.
We have already discussed more here:
R80.x Performance Tuning Tip - Connection Table
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
These are mainly taken from the classes I teach:
1) Using the keyboard number pad to enter digits that are part of the admin password or SIC activation key, but Num Lock is not set. This results in junk becoming part of the password/key and having to reset the password.
2) In SmartConsole pressing "Install Policy" button with unpublished changes pending, being forced to publish the changes, then canceling out of the confirmation screen to actually install policy to the gateway. Administrator then wonders why the changes they just made are not working on the gateway...
3) Accidentally selecting both Security Management Server and Security Gateway checkboxes when running through the post-installation wizard, when a distributed configuration was intended. The Security Management Server ends up with InitialPolicy loaded, and logs from the gateway(s) to the SMS get blocked by it. While the purpose (SMS vs. gateway) can be changed on an existing system by hacking the registry through cpprod_util and such, it is much cleaner and safer to just completely reload the system with Gaia and select only the correct checkboxes.
4) Unchecking "Drop out of state TCP packets" on the Stateful Inspection screen of Global Properties during troubleshooting, and forgetting to recheck it.
5) Defining slow or invalid DNS servers in the Gaia OS of the gateway, this causes all kinds of nasty issues with the rad daemon and domain-based objects among others...
6) Dropping/Rejecting/Blocking traffic in the policy, but not setting Track to log. I call this the "roach motel" effect. There is an exception to this of course for dropping but not logging "trash" or "noise" traffic such as subnet and NetBIOS broadcasts.
7) Using multiple embedded nested groups in the antispoofing topology definitions for the gateway, this will bite you eventually. This can be somewhat avoided by using groups in the gateway topology definitions that are exclusively used for antispoofing enforcement and nothing else, and they are clearly marked/named as such.
8) Placing the host IP or network number/mask in the name of the object, but it doesn't actually match the value defined in the object itself. Been bitten by that one...
9) Making a typo in the network portion of an address used in an automatic or manual NAT definition, or even in a manual proxy ARP definition. Logs say everything is fine, but it simply doesn't work because the return traffic is not coming back to your firewall. Very difficult to figure out if you don't spot the typo.
10) Performing a migrate import (upgrade_import) on an SMS thinking it will merge whatever configuration is currently present on the SMS with what is being imported. It won't, anything currently in the configuration of the SMS (including SIC certificates and the ICA) will be destroyed.
11) Believing you need a "Any Any Any Accept" rule at the bottom of an ordered APCL/URLF or Threat Prevention policy (or even explicit rule allows for internal to internal traffic). You don't since the implicit cleanup rule's action in these types of policies is an Accept, not a Drop since these layers are usually implemented as blacklists, not whitelists. Doing so will adversely affect SecureXL acceleration.
12) Not realizing that when searching for logs in SmartLog or the Logs & Monitor tab of SmartConsole, that any unquoted space will be treated as a logical AND operation, not an OR operation or a phrase search.
13) Using Internet Explorer instead of literally any other browser to interact with the Gaia web interface. Works but is dog slow.
14) Unchecking any boxes on the NAT Properties screen of Global Properties. Just don't, unless you want some serious pain.
15) Disabling the spanning tree protocol (STP) on any switches in your network, you will pay dearly when a bridging loop forms. This is *not* the same thing as setting portfast.
Those are the ones I can think of off the top of my head, I'm sure I could come up with a few more...
--
"IPS Immersion Training" Self-paced Video Class
Now Available at http://www.maxpowerfirewalls.com
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I have tried to reproduce the issue number 2, however it was not replicated.
Could you elaborate and specify, which changes you have performed?
Could you please detailed the scenario- in order to reproduce it .
Thanks in advance
Valery
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very nice points Timothy!
And a few more points from me:
1) Do not enable all blades to test them. Some settings will remain in the rules for a lifetime. This only increase the size of the ruleset and the installation will take longer. Better set up a test environment under VMWare and use eval licenses to test blades.
2) Do not use the same default password for all company systems, gateways,..:-)
3) Disable: Bypass IPS inspection when gateway is under heavy load.
I'd leave that on all the time to prevent performance problems
4) Missing stealth rules at the beginning of the ruleset.
5) Optimizatize the rules for SecureXL and not necessarily according to the company logic.
6) Do not use Domain objects. They reduce the performance of the gateway. If you want to use them, then at the end of the set of rules.
7) Do not disable all firewall implied rules in global properties. Unless you know exactly what you're doing and created your own implied rules in the rulesset.
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1) Try not to create multiple objects for the same host/network definitions.
2) Keep on top of removing unused objects and rules with zero hit count.
3) Make sure rule names and comments are clear and descriptive.
4) Not having a tested backup and recovery procedure. (This will come and bite you at some point)
There are some amazing suggestions here in the previous comments, I certainly will be making a compiled list for quick reference in the future.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nice ones!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Don't enable IPS for all traffic.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nice one. And following on from that, tune the IPS policy in terms of enabled/disabled protections.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
With IPS and Thread Prevention, I think it's a good to look at the networks and the events where used.
With the IPS system it is also important which profiles you use:
default profile -> low performance impact, low security level
recommanded profile -> high performance impact, high security level
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Completely agree. It all depends on the networks function and gateway placement. SCADA/ISC networks have different requirements/tech than say traffic egressing through a perimeter gateway.
Also having processes in place to review IPS protection status as and when new systems are put in place.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Having relevant architecture/design and operating procedures in place will and can avoid configuration errors from happening in certain areas.
Especially in organizations that may have different tiers of security personnel with varying knowledge of the platform.
I'm a bit of a sucker for a good design and firewall Architecture that defines, naming standards, colour coding of objects, IPS review etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1. Not documenting your network topology. I've seen some circular dependencies knocking infrastructures offline when admins were not taking overall traffic paths into account.
2. Referring to rules by they numbers in documentation or email. Again, I've seen this being done in the mail thread and shortly thereafter, new rules were introduced into policy that skewed that data. Admins used the mail thread for references afterwards and the mayhem ensued.
3. NTP. Use internal to your organization NTP servers for all of your infrastructure components. Use external NTP only as sources for your NTP servers and make sure all of the NTP references are uniform. Monitor NTP drift and sync and be alerted if it is out of bounds you know are acceptable. There are some excellent free solutions that will allow you to achieve this https://www.meinbergglobal.com/english/sw/ntp.htm
Otherwise:

...time is wasted when troubleshooting.
4. Keeping hypervisor snapshots on VMs running Check Point management or gateways.
5. Making Gaia snapshots of the vSEC instances,
6. Not saving Gaia configuration files for recovery or versioning.
7. Allowing asymmetric routing (with all the settings modified to accommodate this possibility), please DO NOT.
8. Upgrading to new major releases before training for, or learning their specifics.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Danny Jung gave a very good presentation on this topic at the CPX in Vienna. Danny you should publish it.
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's how it looks on many firewalls after years .
.
Check your ruleset over and over again or use nice tools for that.

➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
More good points Heiko, but concerning this one:
> 3) Disable: Bypass IPS inspection when gateway is under heavy load.
> I'd leave that on all the time to prevent performance problems
The IPS Bypass Under Load function has not really been properly updated since CoreXL was introduced, and was originally intended for use on a gateway with only one INSPECT driver/kernel instance. Here is the verbiage covering this from my IPS Immersion Class:
This controversial feature will disable all IPS inspection completely (essentially running the ips off command) when both High
Thresholds are exceeded, and re–enable IPS inspection when both Low thresholds are met. Note that all it takes is for ONE
Firewall Worker core (kernel instance) to reach these thresholds for IPS enforcement to be disabled on ALL Firewall
Worker cores FOR THE ENTIRE GATEWAY. See the following SK for more information about this potentially unexpected
effect: sk107334: IPS Bypass is triggered even when CPU utilization is not over the defined threshold
So the effect I've seen in the real world is that if the Bypass Under Load is set and the gateway is reasonably busy, there will almost always be a core over the threshold and IPS is completely disabled practically all the time. Since the above was written I've received reports that it is actually ANY one core on the gateway going over the thresholds (including SND/IRQ Cores) that can cause an IPS bypass. On a poorly tuned firewall in the real world with IPS Bypass Under Load enabled the overall result is: no IPS enforcement at all.
--
"IPS Immersion Training" Self-paced Video Class
Now Available at http://www.maxpowerfirewalls.com
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1) Start "migrate export" script as cronjob on management server.
PS: That's what I've wanted for a long time as a GUI function.
2) Allow only used VLAN's on switch trunk ports (802.1q).
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Don't have a outbound NAT ALL rule at the bottom of your NAT rulebase that hides all your traffic behind the cluster/gateway main IP (including all internal traffic). I've seen this and it resulted in having to create a huge amount of No NAT rules to make internal systems work, not only that but a lot of head scratching to determine why the systems didn't work until the "penny drops" with the NAT rule.
Instead, use the "Hide internal networks behind the Gateways external IP" for outbound traffic to the internet and then create the specific NAT rules that are required.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with you Timothy!
I always set the thresholds to very high values for high, e.g. 98% or 99%, so that should never be the case. But - I agree with you - the case occurs with 100% CPU, e.g. during the policy installation or when a core is asymmetrically exhausted. If I often have problems with it, then a performance tuning has to be done:-)

From my point of view there is also a time threshold to be added. E.g. If 100% more than 10 seconds.
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do not use the name "fw1" as gateway name.
If you migrate the management from R77.30 to R80.10+ you will get an error. Under R80.10, the service with the name fw1 is recreated. Now the name exists twice, once as gateway "fw1" and once as service "fw1". Neither of the objects can be deleted or renamed under R80,10+. So this is an own goal and the policy cannot be installed under R80,10+ .
Solution:
Back to version R77.30 and rename gateway. Then again the migration to R80.10+.
PS:
"fw1" is a very old service under version 4.0 and 4.1 and is no longer used since 15-20 years. It could also be deleted automatically when migrating to R80.10. The service is also available in the implied rules under R7x and R8x. Version 4.1 is not used anymore![]() .
.
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do not use the same cluster ID for two directly connected cluster!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike Brenner, I think this particular issue is now addressed in R80.x. There is no longer a configurable "Cluster ID" field in FTW.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would disagree regarding domain objects from R80.10 onwards. They are great, we love them. "Legacy" FQDNs indeed were unusable.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What's the issue using getting interfaces with topology? Works like a clock as long as your routes are identical on all cluster members. We run it religiously - haven't seen any problems R77.30 onwards at least. ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Get Interfaces with Topology automatically creates Network Objects that is a pain to get read of.
If you happen to have a boatload of static routes on the gateways, it will iterate creation of the same network objects for each gateway appending "_#" to them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Set Cluster ID:
R70.x - R77.20
$FWDIR/boot/modules/fwkern.conf
fwha_mac_magic=VALUE
fwha_mac_forward_magic=VALUE
R77.30
$FW_BOOT_DIR/ha_boot.conf
cluster_id VALUE
R80.10+
# guidbedit.exe
> table > Network-Objekts > network_objekts > [Clustername]
> cluster_magic > change VALUE
> SmartDashbord Policy Install
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 31 | |
| 6 | |
| 3 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |
Upcoming Events
Thu 20 Aug 2026 @ 08:30 AM (COT)
Medellin: Workspace Evolution: Hybrid Mesh Management - Visibilidad, Automatización e IAThu 20 Aug 2026 @ 10:00 AM (PDT)
AI Security Masters E13: READY OR NOT: Securing the AI Ent 5/5 - AI Research & Threat LandscapeThu 20 Aug 2026 @ 10:00 AM (PDT)
AI Security Masters E13: READY OR NOT: Securing the AI Ent 5/5 - AI Research & Threat LandscapeThu 20 Aug 2026 @ 08:30 AM (COT)
Medellin: Workspace Evolution: Hybrid Mesh Management - Visibilidad, Automatización e IAThu 20 Aug 2026 @ 06:00 PM (COT)
Medellin: Workspace Intelligence: IA Generativa en Acción para Equipos de SeguridadAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter