I am not sure if my fw monitor filter is correct
192.168.55.55 = DNS server
192.168.49.49 = standby gateways IP
I never see the actual DNS request, just the reply
[Expert@redacted:0]# fw monitor -F 0,0,192.168.55.55,0,0 -F 192.168.55.55,0,0,0,0
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=231 id=8482
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=231 id=8482
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8483
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=144 id=8484
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=128 id=8485
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=162 id=8486
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=177 id=8487
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8488
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=151 id=8489
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=180 id=8490
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=156 id=8491
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8483
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=144 id=8484
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=185 id=8492


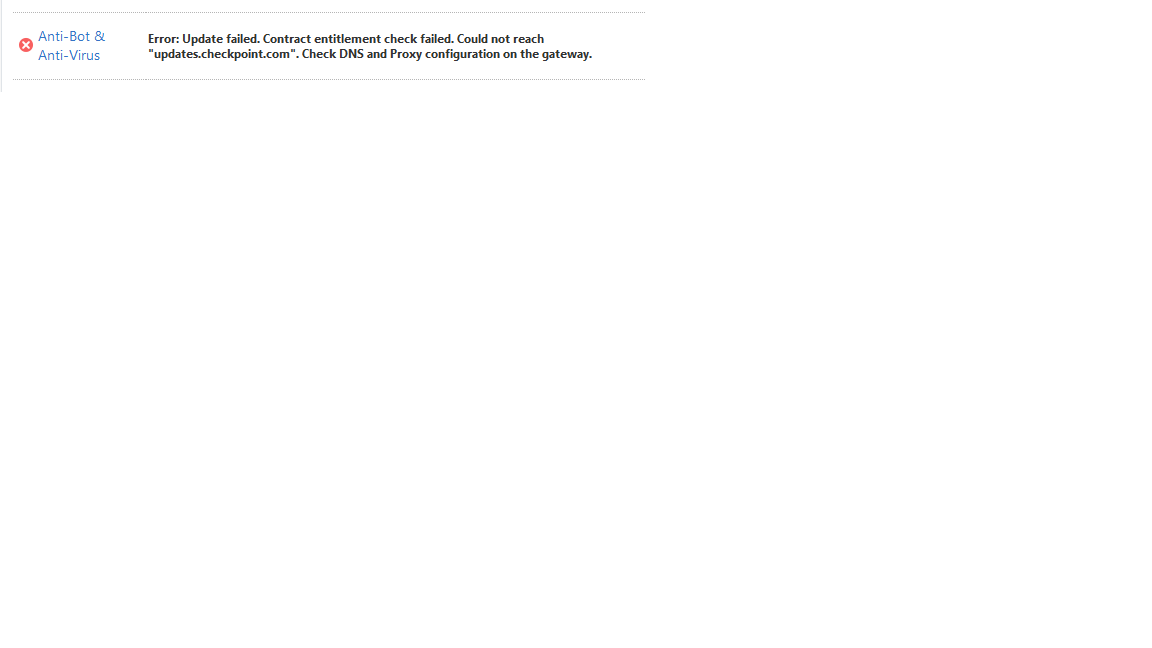{kind=link}