- Products
Network & SASE IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SASE SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloud Cloud Network Security CloudMates General CloudGuard - WAF Talking Cloud Podcast Weekly ReportsSecurity Operations Events External Risk Management Incident Response Infinity AI Infinity Portal NDR Playblocks SOC XDR/XPR Threat Exposure Management
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
CheckMates Fest 2026
Join the Celebration!
AI Security Masters
E1: How AI is Reshaping Our World
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
Watch NowOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
Maestro Madness
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Security Gateways
- :
- Re: DNS not working on gateway with internal DNS s...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
DNS not working on gateway with internal DNS servers
I have a active/standby HA cluster of two security gateways running 80.40 with ga jumbo take 139 installed.
On one of the cluster members name resolution simply will not work when my internal DNS servers are configured to be used:
[Expert@gatewayb:0]# nslookup
> google.com
;; connection timed out; trying next origin
;; connection timed out; no servers could be reached
If I configure public DNS servers 8.8.8.8 and 4.2.2.2 DNS starts working right away and the gateway shows as healthy in SmartConsole.
Looking at traffic logs I see the DNS request being sent to my internal DNS server.
I did a tcpdump on the interface that is closest to the DNS server and I am only seeing the DNS responses not the actual requests.
I noticed on the log card the DNS request is being received by the sync interface. I don't understand why. Could this be the issue? The sync interface is directly connected to the second security gateway. The problematic gateway is currently the standby member.
I can't leave DNS set to public servers as that causes problems with our updatable objects resolving to different IP's than what our internal hosts use.
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This problem has been mentioned here earlier and for the R80.40 the recommendation has been to stick to the default behavior as it "should be working".
If the new mode is active: fwha_cluster_hide_active_only = 1, then cluster hide is working well for external services *only*, outgoing connections go via the sync interface to the active and active replaces source IP of the standby node with the cluster VIP. Returning packets come back to the active, from the active via the sync interface back to the standby.
All nice and clear? Well, not entirely, if you happen to have very old licenses which do not permit forwarding traffic between external interfaces. Opened a case, got a workaround, which included static routes to other cluster node via the sync interface in both cluster nodes.
The fun part begins when the service (NTP, DNS, RADIUS, you name it) sits in the internal directly connected network as you have described. I have a support case open for several months already, where I described exactly the same problem and wanted a solution for keeping the "new mode" active and making this mode usable for the standby ClusterXL node. It was initially mentioned to the support that we are aware that the "old mode" works fine, but we would like to keep the default "new mode" active and have a fix/solution for this mode.
Today I had yet another session with the support specialist and the support specialist said he doesn't have any working solution besides hacks we know already and hopefully we can arrange a call with developers to discuss the topic further.
An ugly workaround to make internal DNS working again (which I personally don't like):
Create a permissive rule for returning packets from the DSN server: src:internal DNS server dst:firewall nodes service:udp high port range.
Roll-back to the "old mode", which disables forwarding packets via the sync interface:
fw ctl set int fwha_cluster_hide_active_only 0
17 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That could be an issue if it goes to your sync interface...
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is it going to the sync interface because it is the standby cluster member? It's like the gateway sources the packet from itself and receives it on the sync interface.
This scenario happened about half a year ago where internal DNS servers would not work and I resolved it by configuring public DNS servers, cpstop/cpstart, then changed the DNS servers back to my internal ones, cpstop/cpstart, and they worked fine.
This fix is not working this time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Take a look at sk167453 and section 3.4 of sk169154
Suggest doing so in consultation with TAC.
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I took a look at those sk's. From what I gathered it is normal for the standby gateway to send to to the active using it's sync interface but it seems the process that exists to correct this async routing isn't working.
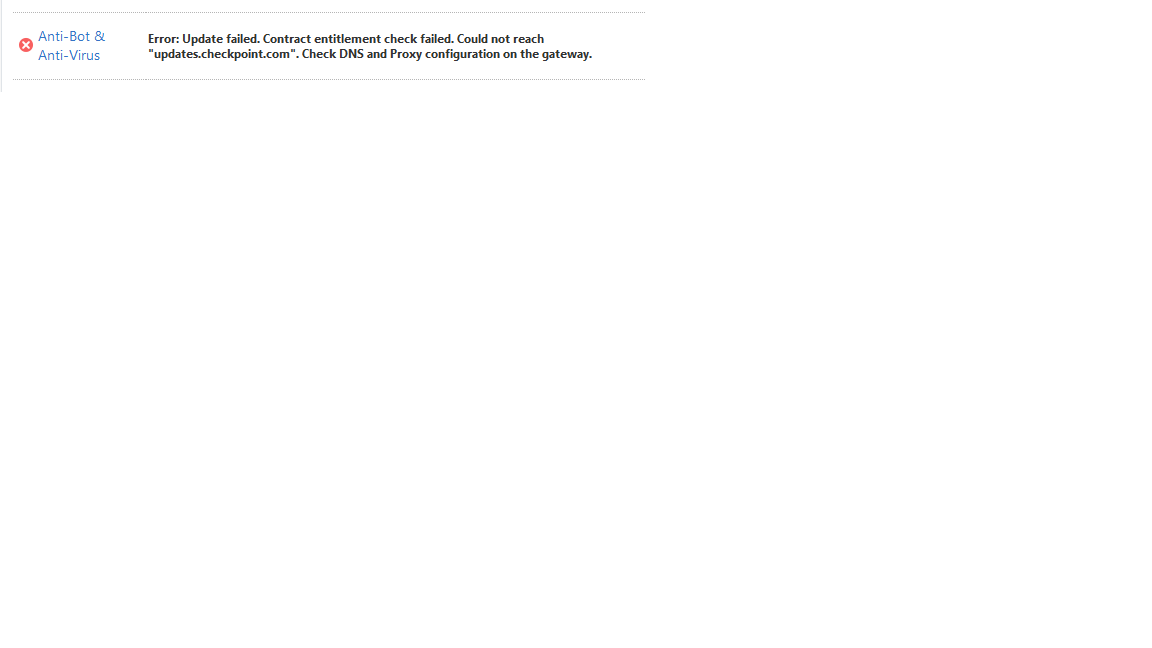
With the standby member the way that it is now it can't reach updates.checkpoint.com or anything else to verify licensing. See attached screen shot.
My fear is if I make the standby active connections will be dropped and take my environment down as this is what happened to me on 80.30 when DNS would not work.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, dont risk it then, understood...can you do fw monitor on DNS servers IP and send us the output? Maybe also have TAC verify all this with you.
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure if my fw monitor filter is correct
192.168.55.55 = DNS server
192.168.49.49 = standby gateways IP
I never see the actual DNS request, just the reply
[Expert@redacted:0]# fw monitor -F 0,0,192.168.55.55,0,0 -F 192.168.55.55,0,0,0,0
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=231 id=8482
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=231 id=8482
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8483
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=144 id=8484
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=128 id=8485
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=162 id=8486
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=177 id=8487
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8488
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=151 id=8489
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=180 id=8490
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=156 id=8491
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=164 id=8483
UDP: 53 -> 36749
[vs_0][fw_2] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=144 id=8484
UDP: 53 -> 36749
[vs_0][ppak_0] eth7:i[44]: 192.168.55.55 -> 192.168.49.49 (UDP) len=185 id=8492
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Which interface is eth7? By the way setting @Olavi_Lentso mentioned is most likely relevant here. I checked on one of my customer's R80.40 fw and it shows option is set to 1 by default, but they dont have this problem. You may wish to change it and test. No need to reboot.
fw ctl get int fwha_cluster_hide_active_only
fwha_cluster_hide_active_only = 1
Just run fw ctl set int fwha_cluster_hide_active_only 0
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Interface eth7 is the interface you would expect to reach the DNS server on if traffic flowed directly from the standby cluster member to the DNS server.
192.168.55.55 - DNS server
[Expert@Mredacted:0]# ip route get 192.168.55.55
192.168.55.55 via 192.168.49.46 dev eth7 src 192.168.49.49
cache
[Expert@redacted]#
I ran fw ctl get int fwha_cluster_hide_active_only and it indeed does return a value of 1.
To use fw ctl set int fwha_cluster_hide_active_only 0 , do I have to run this on both cluster members?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Normally, you just run those commands on whichever one is active, but in your case, I would do on both and dont reboot, maybe just push policy before testing, though technically, thats not required.
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will fwha_cluster_hide_active_only 0 survive a reboot? If not how can I make it stay?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Personally, I would not do that, unless you confirm it works on-the-fly. But, here is how you do it:
Say, just as stupid example, kernel value is test123456 and you wish to change it to 1, all you do is cd $FWDIR/boot/modules and do ls to check if fwkern.conf is there and if not, then just run touch fwkern.conf to create it.
Once file is created, just use vi to edit it and add kernel value, so in this case, say test123456=1 and save the file and thats it, do same on both members. That survives reboot 100%.
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I ran fw ctl set int fwha_cluster_hide_active_only 0 on both cluster members and that indeed resolved the DNS issue!
I am just waiting for the standby member to update it's license info with Check Point and then it should show as healthy in SmartConsole.
I did open a TAC case this morning on the issue but didn't hear back yet.
I will update the case with this new information and see how they want me to proceed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good deal and thanks to @Olavi_Lentso for pointing out the right setting. You may want to check with TAC why this is causing issue in your environment, because it 100% should not. Ah, word "should", its favorite IT word : - )
Let us know what they say.
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This problem has been mentioned here earlier and for the R80.40 the recommendation has been to stick to the default behavior as it "should be working".
If the new mode is active: fwha_cluster_hide_active_only = 1, then cluster hide is working well for external services *only*, outgoing connections go via the sync interface to the active and active replaces source IP of the standby node with the cluster VIP. Returning packets come back to the active, from the active via the sync interface back to the standby.
All nice and clear? Well, not entirely, if you happen to have very old licenses which do not permit forwarding traffic between external interfaces. Opened a case, got a workaround, which included static routes to other cluster node via the sync interface in both cluster nodes.
The fun part begins when the service (NTP, DNS, RADIUS, you name it) sits in the internal directly connected network as you have described. I have a support case open for several months already, where I described exactly the same problem and wanted a solution for keeping the "new mode" active and making this mode usable for the standby ClusterXL node. It was initially mentioned to the support that we are aware that the "old mode" works fine, but we would like to keep the default "new mode" active and have a fix/solution for this mode.
Today I had yet another session with the support specialist and the support specialist said he doesn't have any working solution besides hacks we know already and hopefully we can arrange a call with developers to discuss the topic further.
An ugly workaround to make internal DNS working again (which I personally don't like):
Create a permissive rule for returning packets from the DSN server: src:internal DNS server dst:firewall nodes service:udp high port range.
Roll-back to the "old mode", which disables forwarding packets via the sync interface:
fw ctl set int fwha_cluster_hide_active_only 0
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Buddy if possible connect a DNS server in a DMZ interface for best practices.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In my scenario the culprit was a “ no NAT” rule that involved the network of the internal interfaces of the security gateways and the network the DNS servers are on.
This prevented the new 80.40 feature from NAT’ing the standby members ip to the cluster VIP when the request left the active members interface towards the DNS server
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For private network ranges usually there is need to create nonat rule when the the destination is in private range, otherwise firewalls would use private -> internet nat and translate private -> private traffic, which should be avoided.
We tested with the CP support and created a dedicated nat rule for internal dns before the generic nonat rule, but unfortunately it didn't have any effect, the active node does not replace the src ip of the standby.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 19 | |
| 17 | |
| 8 | |
| 8 | |
| 5 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |
Upcoming Events
Thu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 12 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 3: Exposing AI Vulnerabilities: CP<R> Latest Security FindingsThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2025 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter