- Products
Quantum
Secure the Network IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloudGuard CloudMates
Secure the Cloud CNAPP Cloud Network Security CloudGuard - WAF CloudMates General Talking Cloud Podcast - Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Quantum (Secure the Network)
- CloudGuard CloudMates
- Harmony (Secure Users and Access)
- Infinity Core Services (Collaborative Security Operations & Services)
- Developers
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Infinity Portal
- Products Announcements
- Threat Prevention Blog
- CheckMates for Startups
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
May the 4th (+4)
Roadmap Session and Use Cases for
Cloud Security, SASE, and Email Security
SASE Masters:
Deploying Harmony SASE for a 6,000-Strong Workforce
in a Single Weekend
Paradigm Shifts: Adventures Unleashed!
Capture Your Adventure for a Chance to WIN!
Mastering Compliance
Unveiling the power of Compliance Blade
CPX 2024 Content
is Here!
Harmony SaaS
The most advanced prevention
for SaaS-based threats
CheckMates Go:
CPX 2024 Recap
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Quantum
- :
- Security Gateways
- :
- Is it advisable to change affinity in my scenario?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is it advisable to change affinity in my scenario?
Hi Folks,
One of our customers is having 4800 devices with 8 GB RAM. This is a kind of ISP environment and we are still on R77.30 due to Management HW appliance. We are about to move to Open-server license and then we will migrate it to R80.30.
Meantime this firewall has an NGFW license and we are protecting DNS queries and Syslog servers behind the firewall. Being an ISP environment we are seeing huge queries these days causing all the CPU cores 100% utilized and connection table was carrying almost 600000-800000+ entries at any given time.
Those were previously configured in VRRP cluster which A/P and due to this load it crashed a couple of times over the weekend. Then as an emergency measure, I turned off IPS blade, reduced Virtual session timeout of UDP from 40 to 15 seconds. This has started flushing the connection table rapidly plus converted VRRP to ClusterXL A/A.
This has given a quite breather and CPU1,2,3 has come down to 60-70%; memory almost 1 Gig free now out of 8GB. Now the issue is we are seeing SND 0 is always at 90-98% and this has around 10 interfaces. I am thinking to assign Core 1 to SND but thought to have an advice from the community.
Can someone please advise?
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
26 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It will help if you provide the output of the S7 commands:
Also, are these queries legitimate or just background noise from Internet ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Those are genuine queries for sure wondering if Firewall_worker_core can be reduced.
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The Super 7 outputs will really help, but based on what you have provided so far:
1) Disable state sync for the domain-udp and domain-tcp services by unchecking "Synchronize connections on cluster" on the Advanced screen of these services. Also do this for any other services you have defined on port 53. This will reduce your state sync traffic significantly and lessen CPU loads on your firewall workers (cores 1-3).
2) By disabling IPS, it is likely that a large amount of traffic is now being accelerated by SecureXL assuming that you don't have APCL/URLF or any other Threat Prevention blades enabled (need to see output of enabled_blades command). This is why your lone SND core has become so heavily utilized. If you plan to leave IPS off, you should probably reduce the number of Firewall Workers/instances from 3 to 2 for a 2/2 split. If you plan to turn IPS back on, leave the 1/3 split as-is and try to disable any IPS protections with a Critical performance impact rating, and to a lesser extent those with a "High" performance impact rating.
3) Assuming you have a reasonably recent R77.30 Jumbo HFA loaded, enable the Dynamic Dispatcher to help keep the firewall workers balanced.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yeah - I did that and almost sure that device is handling too much of connections. Those are mostly legit.
Now the thing here is; I am trying to find out the concurrent connections/sec and the basis on I am seeing if the appliance can really handle those many connections?
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
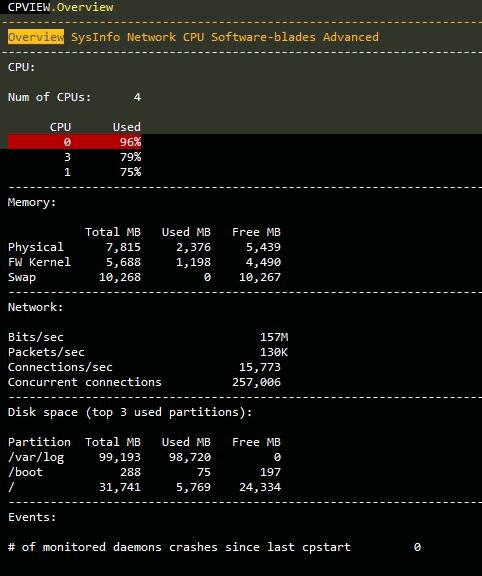
cpview will show you the concurrent connections as well as new connections/sec right on the Overview screen. Would be interesting to see those numbers, your 4-core 4800 is not exactly a powerhouse.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the output from both my firewalls.
[Expert@FW-1:0]# cphaprob stat
Cluster Mode: Load Sharing (Unicast) with IGMP Membership
Number Unique Address Assigned Load State
1 (local) 10.10.10.1 30% Active (pivot)
2 10.10.10.2 70% Active
[Expert@FW-1:0]# fw tab -t connections -s
HOST NAME ID #VALS #PEAK #SLINKS
cpview
localhost connections 8158 313527 627991 1229492
[Expert@FW-2:0]# fw tab -t connections -s
HOST NAME ID #VALS #PEAK #SLINKS
localhost connections 8158 501978 633566 1981870
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Things look very busy and changing to a 2/2 split is not likely to help much and will probably cause the FW Workers to get overloaded next. How much Internet-routable space is this firewall cluster protecting? /24? /16? You may have a lot of drops and the penalty box might help.
We may be able to tune things up a bit, please provide output of command enabled_blades and the Super 7 outputs:
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok - I had reduced the virtual session timeout to 10secs and all the CPU cores were spiked up. Now I increased it to 20 and this is the thing plus top 7 command out put from FW2
Accelerator Status : on
Accept Templates : enabled
Drop Templates : disabled
NAT Templates : disabled by user
Accelerator Features : Accounting, NAT, Cryptography, Routing,
HasClock, Templates, Synchronous, IdleDetection,
Sequencing, TcpStateDetect, AutoExpire,
DelayedNotif, TcpStateDetectV2, CPLS, McastRouting,
WireMode, DropTemplates, NatTemplates,
Streaming, MultiFW, AntiSpoofing, Nac,
ViolationStats, AsychronicNotif, ERDOS,
NAT64, GTPAcceleration, SCTPAcceleration,
McastRoutingV2
Cryptography Features : Tunnel, UDPEncapsulation, MD5, SHA1, NULL,
3DES, DES, CAST, CAST-40, AES-128, AES-256,
ESP, LinkSelection, DynamicVPN, NatTraversal,
EncRouting, AES-XCBC, SHA256
[Expert@FW-2:0]# fwaccel stats -s
Accelerated conns/Total conns : 336893/344897 (97%)
Accelerated pkts/Total pkts : 40368862/53033972 (76%)
F2Fed pkts/Total pkts : 12664932/53033972 (23%)
PXL pkts/Total pkts : 178/53033972 (0%)
QXL pkts/Total pkts : 0/53033972 (0%)
[Expert@FW-2:0]# fw ctl multik stat
ID | Active | CPU | Connections | Peak
----------------------------------------------
0 | Yes | 3 | 126910 | 241442
1 | Yes | 2 | 136126 | 254097
2 | Yes | 1 | 120311 | 229851
[Expert@FW-2:0]# fw ctl affinity -l -r
CPU 0: eth5 eth1 eth6 eth2 eth7 eth3 Mgmt eth4
CPU 1: fw_2
CPU 2: fw_1
CPU 3: fw_0
All: mpdaemon in.geod vpnd rtmd fwd cpd cprid
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
Mgmt 1500 0 60622990 0 31 0 167160004 0 0 0 BMRU
eth1 1500 0 6689509079 0 13666646 0 2631882696 0 0 0 BMRU
eth1.6 1500 0 0 0 0 0 23037 0 0 0 BMRU
eth1.9 1500 0 1344122 0 0 0 1350388 0 0 0 BMRU
eth1.16 1500 0 766633 0 0 0 791501 0 0 0 BMRU
eth1.17 1500 0 12060 0 0 0 17937 0 0 0 BMRU
eth1.18 1500 0 10597686 0 0 0 7753045 0 0 0 BMRU
eth1.19 1500 0 569365 0 0 0 61880 0 0 0 BMRU
eth1.20 1500 0 922907 0 0 0 965252 0 0 0 BMRU
eth1.22 1500 0 10983 0 0 0 19357 0 0 0 BMRU
eth1.52 1500 0 6187725335 0 0 0 2179626933 0 0 0 BMRU
eth1.54 1500 0 0 0 0 0 29 0 0 0 BMRU
eth1.62 1500 0 2971 0 0 0 34 0 0 0 BMRU
eth1.95 1500 0 30796 0 0 0 29041 0 0 0 BMRU
eth1.96 1500 0 48543698 0 0 0 64899856 0 0 0 BMRU
eth1.97 1500 0 1083676 0 0 0 1223402 0 0 0 BMRU
eth1.98 1500 0 11618 0 0 0 18646 0 0 0 BMRU
eth1.99 1500 0 3763065 0 0 0 1452151 0 0 0 BMRU
eth1.100 1500 0 7320880 0 0 0 7359854 0 0 0 BMRU
eth1.101 1500 0 69986500 0 0 0 64576491 0 0 0 BMRU
eth1.102 1500 0 15195769 0 0 0 31633333 0 0 0 BMRU
eth1.115 1500 0 461373 0 0 0 51875 0 0 0 BMRU
eth1.127 1500 0 9322467 0 0 0 7557092 0 0 0 BMRU
eth1.128 1500 0 1089523 0 0 0 1343511 0 0 0 BMRU
eth1.133 1500 0 10553 0 0 0 19926 0 0 0 BMRU
eth1.134 1500 0 1871397 0 0 0 2081253 0 0 0 BMRU
eth1.136 1500 0 10541 0 0 0 19457 0 0 0 BMRU
eth1.137 1500 0 10514 0 0 0 20033 0 0 0 BMRU
eth1.141 1500 0 31752 0 0 0 40886 0 0 0 BMRU
eth1.143 1500 0 12245 0 0 0 17711 0 0 0 BMRU
eth1.144 1500 0 10897 0 0 0 19816 0 0 0 BMRU
eth1.145 1500 0 11291 0 0 0 18713 0 0 0 BMRU
[Expert@FW-2:0]# enabled_blades
fw vpn
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please provide output of 'ethtool -S eth1'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
[Expert@FW-2:0]# ethtool -S eth1
NIC statistics:
rx_packets: 6883359218
tx_packets: 2701621854
rx_bytes: 1332147014685
tx_bytes: 529218225678
rx_broadcast: 76329986
tx_broadcast: 11708288
rx_multicast: 22448184
tx_multicast: 2704553
rx_errors: 0
tx_errors: 0
tx_dropped: 0
multicast: 22448184
collisions: 0
rx_length_errors: 0
rx_over_errors: 0
rx_crc_errors: 0
rx_frame_errors: 0
rx_no_buffer_count: 2029276
rx_missed_errors: 13822228
tx_aborted_errors: 0
tx_carrier_errors: 0
tx_fifo_errors: 0
tx_heartbeat_errors: 0
tx_window_errors: 0
tx_abort_late_coll: 0
tx_deferred_ok: 0
tx_single_coll_ok: 0
tx_multi_coll_ok: 0
tx_timeout_count: 0
tx_restart_queue: 1
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
tx_tcp_seg_good: 0
tx_tcp_seg_failed: 0
rx_flow_control_xon: 0
rx_flow_control_xoff: 0
tx_flow_control_xon: 0
tx_flow_control_xoff: 0
rx_long_byte_count: 1332147014685
rx_csum_offload_good: 6739151853
rx_csum_offload_errors: 21663
rx_header_split: 0
alloc_rx_buff_failed: 0
tx_smbus: 0
rx_smbus: 0
dropped_smbus: 0
rx_dma_failed: 0
tx_dma_failed: 0
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As I suspected with IPS off you have a pretty large amount of accelerated traffic/pkts (76%) which is why SND 0 is so busy. With those kind of acceleration numbers a 2/2 split is quite likely to help. RX-DRP rate is 0.2% on eth1 which would also be helped by a 2/2 split as eth1 would attach to one SND core and Mgmt would attach to the other via automatic interface affinity. Looks like you already have the Dynamic Dispatcher enabled.
However before we change the split, your 23% F2F is a bit high for the small number of blades you have enabled and is why your Firewall Workers are busy too. Please provide output of fwaccel stats -p to see if that F2F number is caused by high levels of fragmented packets, which will always go F2F in your version. Not much you can do about that other than make sure MTUs are assigned consistently on the network devices you control.
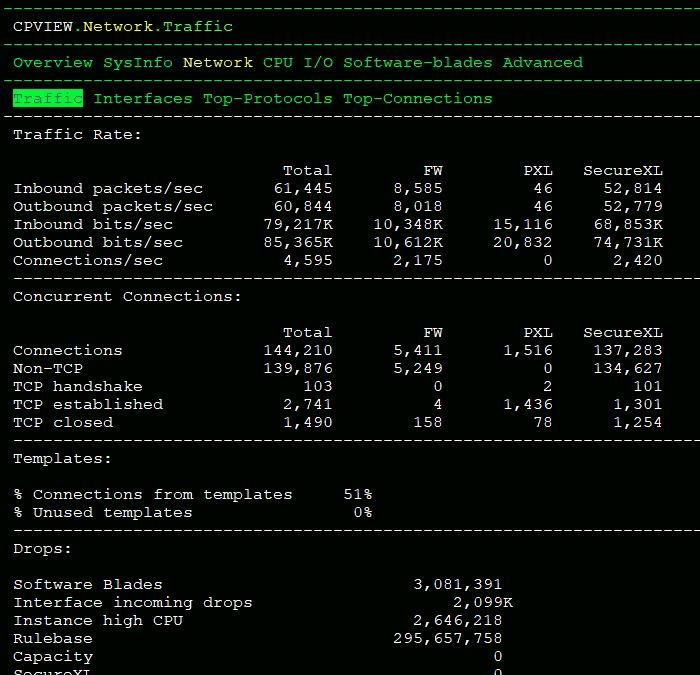
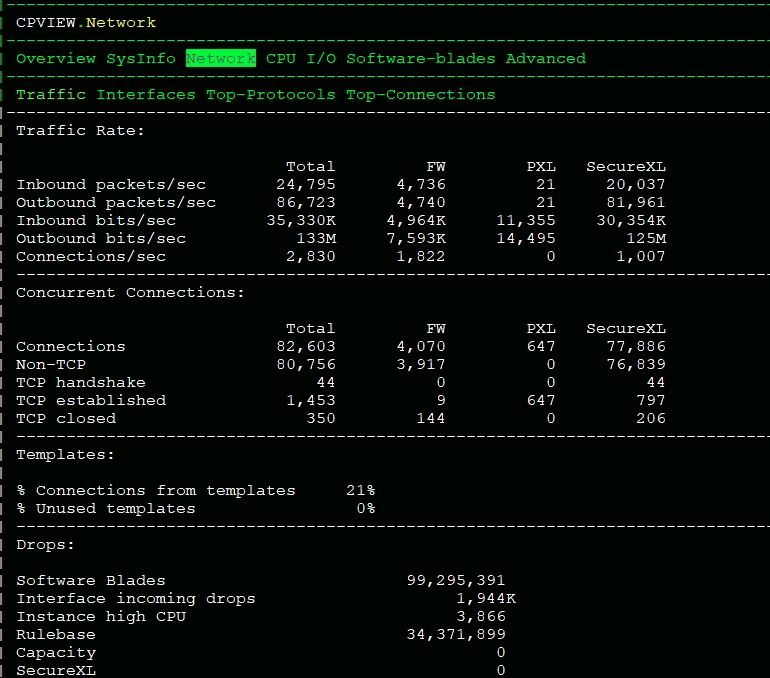
Other possibility for high F2F is a lot of rulebase drops, especially if your Internet-routable space is larger than /24. Please provide a screenshot of the Network...Traffic screen of cpview after scrolling down to show the "Drops:" section. Wait 60 seconds then take another screenshot so we can calculate the drop rate. If this is very high the SecureXL penalty box will help (sk74520: What is the SecureXL penalty box mechanism for offending IP addresses?) avoid the large numbers of rulebase drops happening in F2F on the firewall workers, and let SecureXL efficiently drop the traffic instead on the SND.
If we could get F2F below 10% that would be ideal, and then moving to a 2/2 split is a no-brainer and will help a LOT in your case. 23% F2F might overwhelm the 2 Firewall Workers after the change to a 2/2 split (given current CPU loads with 3 workers) which is why I'd like to see F2F 10% or below first.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
FW-2> fwaccel stats -p
F2F packets:
--------------
Violation Packets Violation Packets
-------------------- --------------- -------------------- ---------------
pkt is a fragment 2684 pkt has IP options 8
ICMP miss conn 1438775 TCP-SYN miss conn 395188
TCP-other miss conn 45349 UDP miss conn 50309547
other miss conn 37 VPN returned F2F 0
ICMP conn is F2Fed 501924 TCP conn is F2Fed 741886
UDP conn is F2Fed 34139 other conn is F2Fed 51834
uni-directional viol 0 possible spoof viol 0
TCP state viol 54497 out if not def/accl 1
bridge, src=dst 0 routing decision err 0
sanity checks failed 0 temp conn expired 789
fwd to non-pivot 0 broadcast/multicast 40282
cluster message 21930793 partial conn 0
PXL returned F2F 0 cluster forward 9992
chain forwarding 0 general reason 0
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May help additionally to increase ring buffer size a little. @Timothy_Hall ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
23% F2F is not due to fragmentation, must be drop rate. Please provide drop stats then moving to a 2/2 split will be the next step, ring buffer size should stay where it is until split change is complete then re-assess RX-DRP.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure !! Customer is investigating from their end as well for maybe for DNS amplification attack. Will provide output in sometime.
Thanks for all your help @Timothy_Hall @HristoGrigorov
Really appreciated!!
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Guys,
Thanks a lot for your help and we were able to mitigate the attack. However still there is a overload on SND/IRQ and let me see what is the load on F2F.
Per @Timothy_Hall if F2F goes below 10% I can change the CORE and assign 1 more core to SND?
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tim is the right person to confirm it but I am personally not going to change any cores assignment until I see all fw workers are constantly above 50% idle time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the current situation - Both are A/A
SND-0 => 70-75%
FW -1-3 => 25-30%
[Expert@FW-1:0]# fwaccel stats -s
Accelerated conns/Total conns : 82119/86595 (94%)
Accelerated pkts/Total pkts : 44371584/54827492 (80%)
F2Fed pkts/Total pkts : 10417718/54827492 (19%)
PXL pkts/Total pkts : 38190/54827492 (0%)
QXL pkts/Total pkts : 0/54827492 (0%)
[Expert@FW-2:0]# fwaccel stats -s
Accelerated conns/Total conns : 142930/149346 (95%)
Accelerated pkts/Total pkts : 121950467/142006719 (85%)
F2Fed pkts/Total pkts : 19932888/142006719 (14%)
PXL pkts/Total pkts : 123364/142006719 (0%)
QXL pkts/Total pkts : 0/142006719 (0%)
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What about to change it only on one member ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's a cluster!! It won't come up for sure due to mismatch in core assignments.
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yeah, right. Can you believe what kind of peculiar requirements there are sometimes 😀
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Looks like the worker CPUs have settled down, in initial screenshots you sent they were 60-70% utilized. I'd say go ahead and make the split change to 2/2, for a cluster you need to treat the change as an "upgrade" and do them one at a time, and the members will not sync properly while they are mismatched so schedule a downtime window.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes it would desirable to get F2F <10% before making the split change to avoid overloading the 2 workers in the new configuration. You can do the split change with F2F >10%, but I would strongly advise at least knowing what is causing that level of F2F before adjusting the split.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So the process to allocate is same, right?
- Run cpconfig
- Select corexl
- Lower down firewall workers to 2
- Exit and reboot
or do I need to use simaffinity.conf file?
Thanks and Regards,
Blason R
CCSA,CCSE,CCCS
Blason R
CCSA,CCSE,CCCS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You got it, just keep in mind the cluster members won't be able to sync their state tables for the brief time they are mismatched.
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also you have no free space left on /var/log. This also may add additional high usage of the cores.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 13 | |
| 12 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |
Upcoming Events
Thu 02 May 2024 @ 10:00 AM (CEST)
CheckMates Live BeLux: How Can Check Point AI Copilot Assist You?Thu 02 May 2024 @ 04:00 PM (CEST)
CheckMates Live DACH - Keine Kompromisse - Sicheres SD-WANThu 02 May 2024 @ 10:00 AM (CEST)
CheckMates Live BeLux: How Can Check Point AI Copilot Assist You?Thu 02 May 2024 @ 04:00 PM (CEST)
CheckMates Live DACH - Keine Kompromisse - Sicheres SD-WANAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2024 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
Facts at a Glance
User Center