- Products
Network & SASE IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SASE SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloud Cloud Network Security CloudMates General CloudGuard - WAF Talking Cloud Podcast Weekly ReportsSecurity Operations Events External Risk Management Incident Response Infinity AI Infinity Portal NDR Playblocks SOC XDR/XPR Threat Exposure Management
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
CheckMates Fest 2026
Join the Celebration!
AI Security Masters
E1: How AI is Reshaping Our World
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
Watch NowOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
R82.10 and Rationalizing Multi Vendor Security Policies
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Management
- :
- Re: Removing orphaned Management HA dependencies
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
Removing orphaned Management HA dependencies
Can someone give me a pointer of how to remove the dependencies for the lost Management HA secondary server from configuration?
I've removed the object from the policies and the destinations for logging, but am seeing:
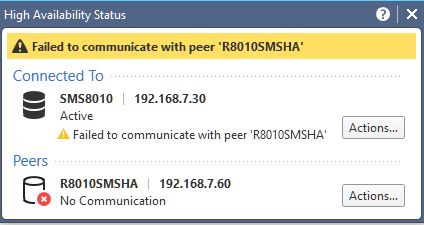
As well as some errors in SmartConsole.
It would be nice to have an option "Remove Server" under "Actions..." button in the "High Availability Status".
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
False alarm: It was a layer 9 error ![]()
Long story short, to clear the record and, in case someone will run into same or similar issue:
At some point, the working version of SMS was cloned on VMWare vSphere and shutdown.
Clone was powered-up. upgraded to Take103 and was in use for the duration of "Missing" time-frame.
The power management configuration in vSphere, retained the name of the original VM to be automatically powered-up when hosts are rebooted.
After reboot of the ESXi, OLD VM running Take91 was powered-up.
This is how the Bermuda Triangle of missing time, logs and versions was formed.
Apologies for the confusion this may have caused.
Vladimir
14 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you perform a database install after deleting the secondary SMS object ? Maybe you should also erase the content (not the directory itself) of the $FWDIR/conf/mgha/ directory. Another possible solution would be a migrate export (including logs) and import in a fresh install. Or ask TAC how to resolve that...
CCSP - CCSE / CCTE / CTPS / CCME / CCSM Elite / SMB Specialist
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gunther,
I've performed the database install and have cleaned-up remaining references to the secondary management.
The message depicted above have disappeared, but something really weird is going on now:
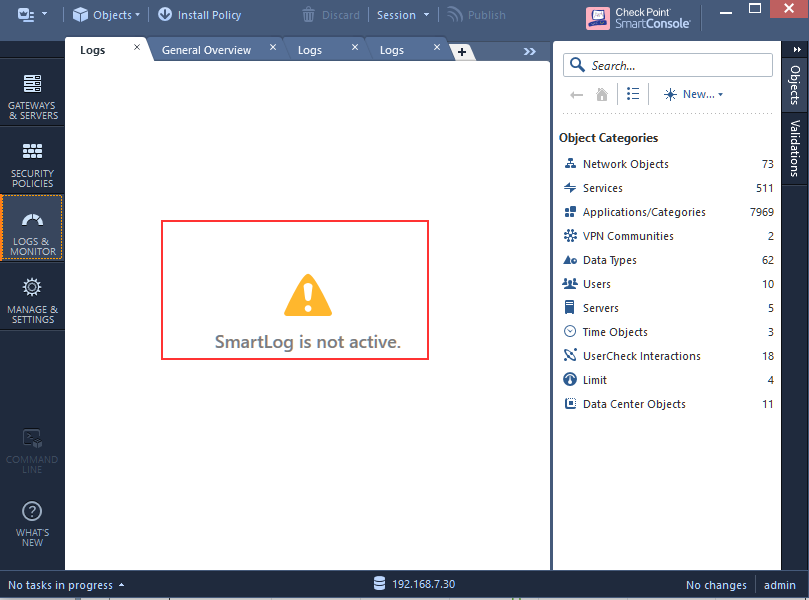
While the Log Indexing on primary SMS is enabled, (SmartEvent and Correlation unit are not).
And upon reboot of the SMS, in "LOGS & MONITOR" I am stuck on "Loading SmartView" after receiving an error popup:

Ant to top it all off, the policy package that was active during removal of the secondary HA SMS is no longer present, the rest of them are.
Thankfully, this is a lab environment, but it is a bit disconcerting.
Connecting to the primary SMS via SSH resulted in the prompt calling to attention changed fingerprint (?).
I am going to try emptying the $FWDIR/conf/mgha/ , reboot, retry the tests and will report my results.
Thank you for your suggestions,
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Removal and installation of the new SmartConsole seemed to remedy the issue with incorrectly reported SmartLog absence and the widget error.
However, the case of missing policy package remains.
Looking here:
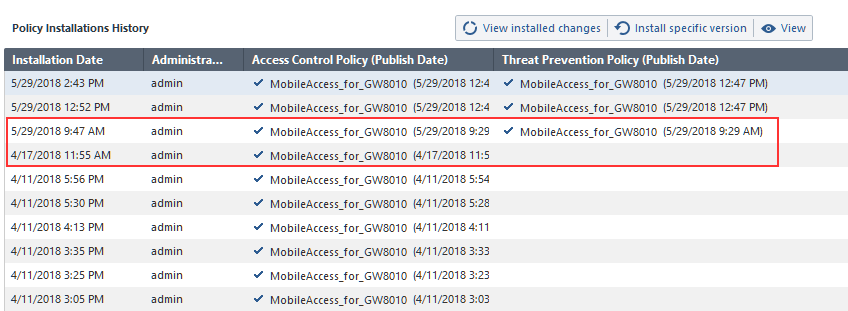
We can see the gap between 4/17/2018 and 5/29/2018. During this time other policy package was installed on selected gateway and there is no trace of it:
> show packages limit 50 offset 0 details-level "standard"
packages:
- uid: "d2797930-9864-4420-b663-62fc308788a4"
name: "Cluster01_Access_Contro_Policy"
type: "package"
domain:
uid: "41e821a0-3720-11e3-aa6e-0800200c9fde"
name: "SMC User"
domain-type: "domain"
- uid: "5bc4f4ac-61f6-43b3-aee9-5d2e754157b0"
name: "XXX-Intra-VPC"
type: "package"
domain:
uid: "41e821a0-3720-11e3-aa6e-0800200c9fde"
name: "SMC User"
domain-type: "domain"
- uid: "2423e123-b989-463c-8ac1-a478a6b5bf06"
name: "MobileAccess_for_GW8010"
type: "package"
domain:
uid: "41e821a0-3720-11e3-aa6e-0800200c9fde"
name: "SMC User"
domain-type: "domain"
- uid: "219dc77c-ea2a-42a7-80a3-cd7da7a2e8bb"
name: "XXXXXXXXX_Simple01_Policy"
type: "package"
domain:
uid: "41e821a0-3720-11e3-aa6e-0800200c9fde"
name: "SMC User"
domain-type: "domain"
- uid: "bb62b9a4-021d-435c-81c5-c95767e76e8e"
name: "Standard"
type: "package"
domain:
uid: "41e821a0-3720-11e3-aa6e-0800200c9fde"
name: "SMC User"
domain-type: "domain"
from: 1
to: 5
total: 5
Just to assure everyone that I am not delirious, I have this screenshot with the policy name beginning in GW8010, in a dated filename: 2018-04-25 14_43_31-SmartConsole (192.168.7.30).png
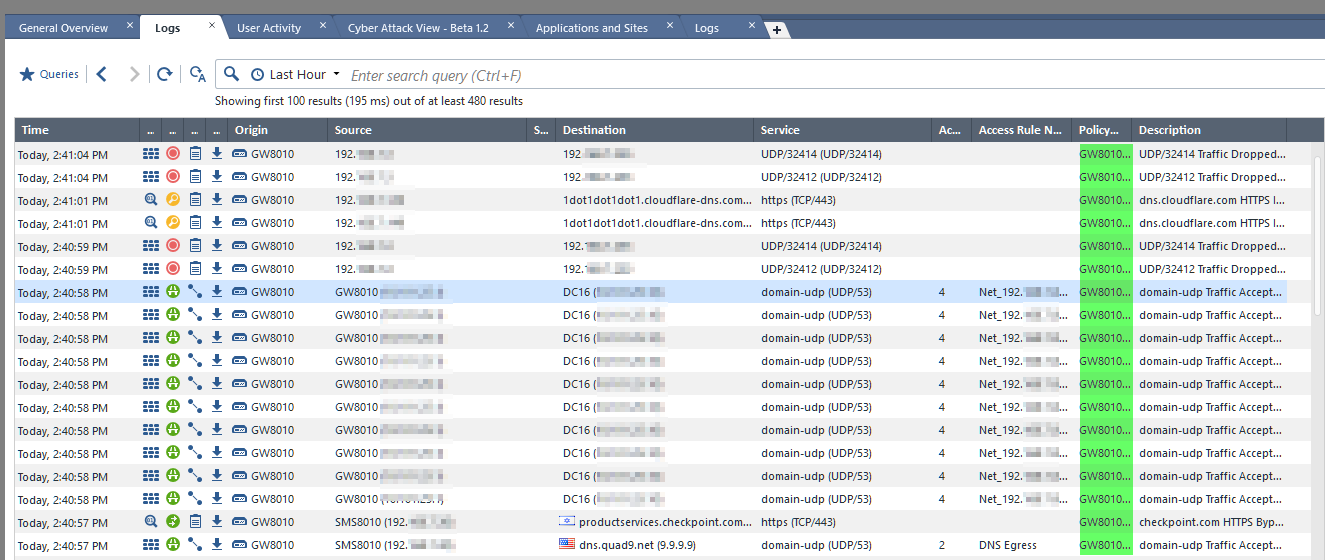
The situation that led to this development:
1. Original licensed SMS was supplemented with Management HA and a dedicated log/SmartEvent/Correlation Unit in trial mode.
2. Upon expiration of the licenses and completion of the PoC, both objects with trial licenses were removed.
3. Problems described above ensued.
I have pored over the R80+ Change Control: A Visual Guide to see if I can find anything in it that could help to solve the mystery, but nothing quite describes the situation when policy packages changes are concerned.
The Audit Log shows similar gap:
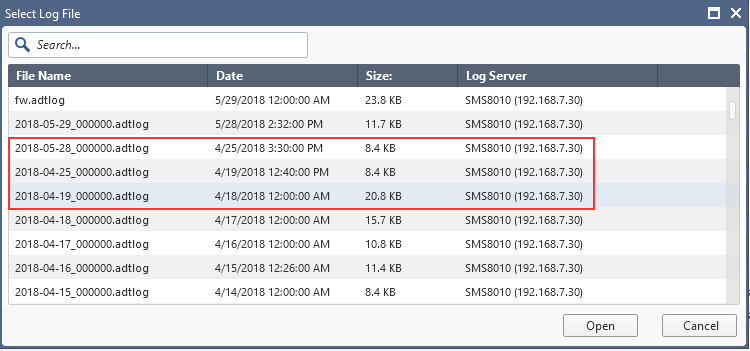
and the only entry that could have shed some light on this situation, dated 2018-04-25, when opened, describes the logswitch on 2018-04-19:
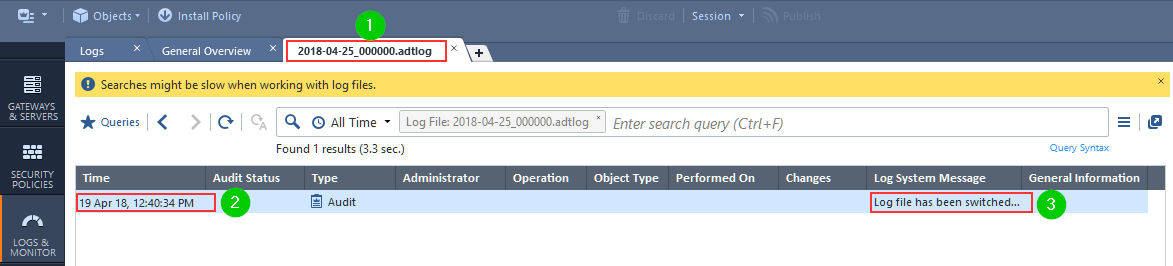
While this does not affect me dramatically, it is quite unnerving to see the policy disappear without a trace.
The SMS8010 is a VM with no snapshots or backups dating anywhere near the days depicted in the logs, so there is no likelihood of it reverting to the state it is in due to unexplained rollback.
Any ideas?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi @Vladimir , would you share how you cleaned up the files? I've got a similar issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @Simon_Taylor , In this case, it was a user error that resulted in this issue. I have just labeled my explanation as "Accepted Solution" in this thread. There was no remediation option.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey, I hope that you managed to take a Gaia snapshot before emptying $FWDIR/conf/mgha/ as this is quite the drastic move... did you manage to see what Check Point Support have to say about this case?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No dice on the snapshot: I've figured the management server's integrity is a suspect anyway and it is a lab, so no production impact even if I'll have to rebuild.
One of these days I'll just script the migrate export to external repository on daily basis.
Same thing with TAC, as this is a NFR licensed environment that was provided to a VAR that does not hold active CP contracts, I have no chance of getting CP Support involved.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After all, i would think that in a VM, Management HA is causing much trouble with nothing in return ! I have found that except in very special topologies / deployments, VM snapshots (together with regular migrate export) and clones are the prefered security measures for SMS. It also reminds of the Dreaded Full Management HA monster  !
!
CCSP - CCSE / CCTE / CTPS / CCME / CCSM Elite / SMB Specialist
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update: The missing policy package was traced to the spontaneously uninstalled JHFA Take_103 and reversion to Take_91.
I've just been working on other systems and wanted to export CPUSE package from my management server when I've noticed that Take_103 is no longer among the installed packages.
Incidentally, after upgrade to Take_103, one of the policy packages went missing.
When system auto-downgraded, it re-appeared, but I've lost the policy package created under the Take_103.
I do not want to alarm anyone, but keep an eye out for mysterious disappearances.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
False alarm: It was a layer 9 error ![]()
Long story short, to clear the record and, in case someone will run into same or similar issue:
At some point, the working version of SMS was cloned on VMWare vSphere and shutdown.
Clone was powered-up. upgraded to Take103 and was in use for the duration of "Missing" time-frame.
The power management configuration in vSphere, retained the name of the original VM to be automatically powered-up when hosts are rebooted.
After reboot of the ESXi, OLD VM running Take91 was powered-up.
This is how the Bermuda Triangle of missing time, logs and versions was formed.
Apologies for the confusion this may have caused.
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Valdimir,
Did you remove the secondary server from the Gateways and Servers view?
Regards,
Adiel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yep:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Valdimir,
So did you remove the links and objects pointing to the secondary before removing the secondary?
Adiel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, otherwise you are informed that the object cannot be removed and you are presented with the "used in" lookup option.
I have no problem in removing it by gradually cleaning-up dependencies. The results are what is of concern, if you have read to the end of the thread.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 23 | |
| 16 | |
| 8 | |
| 6 | |
| 5 | |
| 5 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |
Upcoming Events
Thu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldFri 09 Jan 2026 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 42: Looking back & forwardThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 12 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 3: Exposing AI Vulnerabilities: CP<R> Latest Security FindingsThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldFri 09 Jan 2026 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 42: Looking back & forwardThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter