Hi Howard,
We experienced about the same after upgrading from R77.30 to R80.30. Lots of vague complains by coworkers reporting performance degradation. After about three weeks we managed to solve the issue.
- disabling certain checks in IPS didn't help,
- disabling IPS and Threat Prevention for certain traffic flows didn't help,
- CPU load was only about 10 to 15%, memory load about 10%
- our support partner had no idea and couldn't really help us.
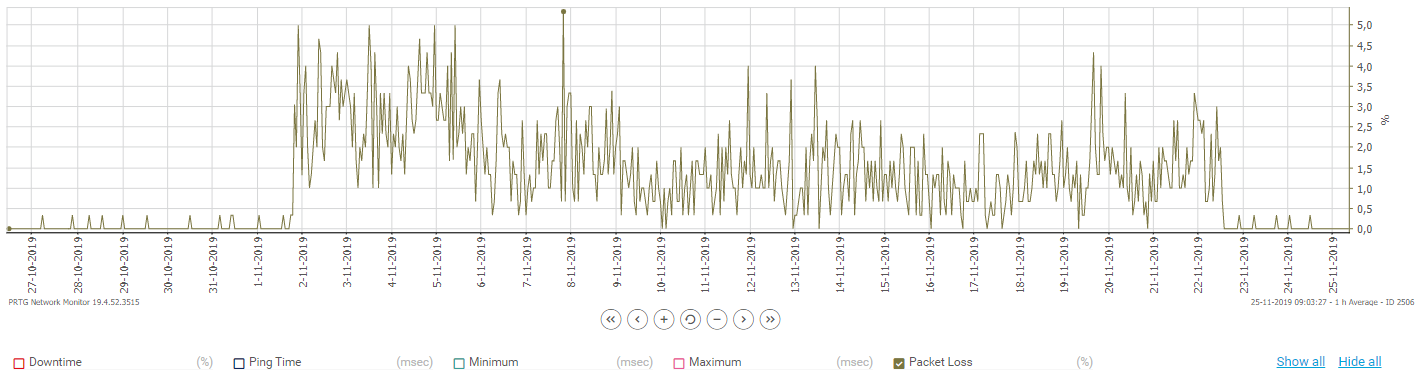
After about 2.5 weeks we found out the troubles seemed to be caused by packet loss. From internet to a loadbalancer we measured about 3% loss. That loadbalancer goes to backend servers, through the firewall again, and about 3% loss as well.
We are running our cluster on VMWare. With use of tcpdump we could proove that:
- packets were always arriving at the CheckPoint VM,
- packets were always leaving the CheckPoint VM (according to tcpdump and fw monitor),
- but packets were not always leaving the hardware where the VM is running.
So it seemed that packets were lost in the layer between the CheckPoint VM and the hardware. Looking for best practices for running CheckPoint on VMware, we found this document:
https://supportcenter.checkpoint.com/supportcenter/portal?eventSubmit_doGoviewsolutiondetails=&solut...
Our VM was configured with E1000 NICs, which seems to be the default on VMWare ESXi 6.0. We changed that to VMXNET3 (remove E1000 NICs, add VMXNET3 NICs) on our Standby Cluster node. After reboot all the interface names and IP's were still correct, so after reboot the cluster was formed in a normal matter. On a quiet moment we did a failover to test the new configuration. 3 days later the graphs of our monitoring look much better. We don't experience packet loss any more. A SCP filetransfer which ran at 1.3MB/s now runs at almost 11MB/s.
So changing from the E1000 driver to VMXNET3 did the trick for us.
Jos


{kind=link}