- Products
Network & SASE IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SASE SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloud Cloud Network Security CloudMates General CloudGuard - WAF Talking Cloud Podcast Weekly ReportsSecurity Operations Events External Risk Management Incident Response Infinity AI Infinity Portal NDR Playblocks SOC XDR/XPR Threat Exposure Management
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
CheckMates Fest 2026
Join the Celebration!
AI Security Masters
E1: How AI is Reshaping Our World
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
Watch NowOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
R82.10 and Rationalizing Multi Vendor Security Policies
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Security Gateways
- :
- Problem accessing standby cluster member from non-...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Problem accessing standby cluster member from non-local network
27 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How about fwha_forw_packet_to_not_active? Helps with similar situations with ping also.
Cluster debug shows "FW-1: fwha_forw_ssl_handler: Rejecting ssl packets to a non-active member"
Try with just entering # fw ctl set int fwha_forw_packet_to_not_active 1, and if works, enable on permanent basis in fwkern.conf.
I hope there is still fwkern.conf on R80.10
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'll give it a shot shortly and let you know if it works.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Kaspars,
The situation is as you described, i.e. accessing from the "other" side.
However, ssh and https traffic to the management interface of the standby member logged as "accepted".
That being said, I'll try adding the route and see if it does the trick.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is what happens if you don't have the specific /32 to the standby. Packet arrives on active FW. It gets accepted and needs to be forwarded to standby box. It will do so based on topology, that is outside interface. But when this packet arrives to standby on outside interface with source IP from inside network, it will get dropped as spoofed. Unless spoofing is off ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah, but I've run the infamous fw ctl zdebug drop on the standby member (not yet in production), and have not seen the drops there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will try tomorrow in one of clusters. Interesting. I just recall seeing spoofing drops in logs. Let you know.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here you go, fw monitor shows packet being accepted on incoming interface on active cluster member. But no outgoing packet there
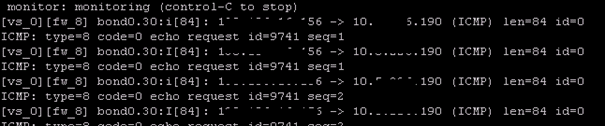
fw ctl zdebug shows on active member

Note that this is without enabling fwha_forw_packet_to_not_active. After I enable it it started working immediately. Without static routes. ![]()
But I have seen your case not that long ago and that's why I remembered about /32 option..
Sorry won't have much time to dig into my past notes what happened there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you again for looking into it: I have not seen the drops because I was looking for them on the standby member, thinking that if I see "accepts" in the log, the primary was not dropping them.
Apparently it drops them on egress.
Of two solutions available, which one do you like better?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hehe, I think I found exactly your situation ![]()
Connection from one side of the ClusterXL destined to the physical IP address of a non-Active cluster member on the other side of the ClusterXL fails - sk42733
I just wanted to mention that this fix with fwha_forw_packet_to_not_active is also connected to many other possible issues:
Simultaneously pinging the cluster members and the VIP address...
"Contract entitlement check failed" error on policy installation failure
Cluster debug shows "FW-1: fwha_forw_ssl_handler: Rejecting ssl packets to a non-active member"
"ERR_CONNECTION_REFUSED" error is displayed in web browser when connecting to Gaia Portal
So, it might be even a "best practice" ![]() But I have only experience with versions before R80, don't know how it is there. Also these "strange" routes might be a bit confusing for a new administrator for example.
But I have only experience with versions before R80, don't know how it is there. Also these "strange" routes might be a bit confusing for a new administrator for example.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree that given how many issues this setting resolves, it may make better sense to have it on by default and have an option of commenting it out.
I wander what is the reason for it not to be and what possible side effects of it being set are.
Vladimir Yakovlev
973.558.2738
vlad@eversecgroup.com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the process of deploying new cluster of 15400s and ended-up using this suggestion.
Just wanted to tip my hat to you.
Thanks,
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had similar problem, solved after setting "fw ctl get int fwha_forw_packet_to_not_active" value to 1. sk42733 was helpful
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You probably trying to connect to IP that's on the "other" side of the firewall and not locally connected IP. If you have only one route to the firewall VIP then traffic will get dropped as spoofed between firewalls. You can create manual static route for IP on the other side to point to standby memebr's locally connected IP interface address
Hope it makes sense ![]()
In other words if you have inside member-act 1.1.1.1 and member-stb 1.1.1.2 with VIP 1.1.1.3. And outside has IPs 2.2.2.1 and .2 and .3 then to connect to 2.2.2.2 via inside interface you will need to add static /32 on the router: 2.2.2.2 next-hop 1.1.1.2
Or I misunderstood maybe the problem?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Kaspars and Alexei, thank you guys!
Ended-up using /32 routes as per Kaspars suggestion since I've recalled being in similar situation before and this being a less intrusive solution.
I will keep Alexei's solution in my toolbox.
That said, I still am baffled as to why zdebug drop did not yield anything on standby member when it was failing.
Regards,
Vladimir
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content


- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
got similar story where
standby device in A/S HA is accessible by IP but GAIA Portal (http2 daemon) isn't working at all
I've regenerated self-signed certs
Still no go
httpd won't start
I can ssh to the standby device but one thing isn't accessible - https/http either on 443 or any other port simply HTTP daemon won't start on that device (there were no chances to that cluster since nearly 1y in terms of the PKI/FQDN etc.)
any ideas folks? alreago got a SR with TAC ![]() just from yesterday.
just from yesterday.
Cheers
Jerry
Jerry
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would say it's a separate issue as you can SSH to standby cluster member. So L3 routing is working end to end. There are multiple SKs regarding dead httpd, really depends on SW version you are running and actual errors you see. You might want to try this
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I did debug even with Ottawa TAC man - still no joy ![]()
Cheers Kaspars, I do appreciate what you've wrote just now but all this is already known, we know it isn't routing or access lists issue but httpd dead as you called it.
now clue what's the problem but that HA runs pretty much latest "takes" ...
Jerry
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just meant to say that this thread probably is irrelevant to your case so best would be to start new one
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I did not nobody replied yet ...
thanks. eot.
Jerry
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
found this SK, but the kern.conf option is not helping.
I'm on R80.20.
As soon as the cluster moves, the connection to the standby node is not possible (neither ping, gaia-ssh, gaia-web).
I'm on a Windows host connected to a server segment (default route to vip) and behind the check point is the management-network with both Check Point nodes (vip + primary, secondary node address). So <myserver> <servernet> <checkpoint><mgmt-net>.
The Gaia management interface is set to the interface, connected in mgmt-net.
Any ideas?
Traffic log says accept SSH/HTTPS but unfortunately I cannot do tcpdumps, due to the fact, that the device is not reachable.
(physical console connect is very complicated here).
Best Regards
Johannes
found this SK, but the kern.conf option is not helping.
I'm on R80.20.
As soon as the cluster moves, the connection to the standby node is not possible (neither ping, gaia-ssh, gaia-web).
I'm on a Windows host connected to a server segment (default route to vip) and behind the check point is the management-network with both Check Point nodes (vip + primary, secondary node address). So <myserver> <servernet> <checkpoint><mgmt-net>.
The Gaia management interface is set to the interface, connected in mgmt-net.
Any ideas?
Traffic log says accept SSH/HTTPS but unfortunately I cannot do tcpdumps, due to the fact, that the device is not reachable.
(physical console connect is very complicated here).
Best Regards
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Johannes
you need to create a TAC to get a accpack fix for this. I was told it will be included in the next omgoing take above take 50.
My TAC are not closed yet because I am missing another fw_wrapper.
for R80.30 take 8 I recieved both accl pack and fw HF to solve it.
I will keep you updated
Best Regards
Kim
Kim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kim,
we are on R80.20 JHF Take 91 GA - should this be included?
Is it a SecureXL problem when reading accpack? It's a 3200 ClusterXL.
R80.30 will need to earn trust in the next month - currently I'm not happy what I see on the community regarding R80.30
Best Regards
Johannes
we are on R80.20 JHF Take 91 GA - should this be included?
Is it a SecureXL problem when reading accpack? It's a 3200 ClusterXL.
R80.30 will need to earn trust in the next month - currently I'm not happy what I see on the community regarding R80.30
Best Regards
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Johannes,
I actually got it fixed on R80.20 and then I lifted the version to R80.30.
I am not sure R80.20 JHF take 91 is included.. then you will need to raise a TAC and asking for fix to "problem accessing standby cluster member from non-local network".
For me the problem is via site2site vpn were I cannot access standby members ssh or Webui. Ping works. Meanwhile I use active member as jump host but this should be fixed can I know R&D fixed it but I don't know if they will port til R80.20 GA version yet?
The issue is not related to appliances type. It is clusterXL in general. Worked in R80.10 but something changed in R80.20 and also in R80.30.
I was very interested in using the Threat Extraction while users surfing the internet. Very nice feature..
What issues are you concerned about in R80.30?
I am very satisfied with the version and for me quite stable so I am interesting to hear concerned about moving to R80.30?
I actually got it fixed on R80.20 and then I lifted the version to R80.30.
I am not sure R80.20 JHF take 91 is included.. then you will need to raise a TAC and asking for fix to "problem accessing standby cluster member from non-local network".
For me the problem is via site2site vpn were I cannot access standby members ssh or Webui. Ping works. Meanwhile I use active member as jump host but this should be fixed can I know R&D fixed it but I don't know if they will port til R80.20 GA version yet?
The issue is not related to appliances type. It is clusterXL in general. Worked in R80.10 but something changed in R80.20 and also in R80.30.
I was very interested in using the Threat Extraction while users surfing the internet. Very nice feature..
What issues are you concerned about in R80.30?
I am very satisfied with the version and for me quite stable so I am interesting to hear concerned about moving to R80.30?
Best Regards
Kim
Kim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kim,
the problem with accessing the standby over VPN is known and I stopped looking for a solution after hearing several times, it's expected behavior. All my customers with IPSec VPNs between corporate sites will get another vendor, who's firewall are able to be monitored by a VPN-remote system. I found a temporary solution by using a dummy-nat construction, but from time to time, the solution doesn't work anymore and we receive monitoring alerts again .... so it's expected behavior and Check Point will not be sold to these kind of customers.
In this case, the problem is without VPN, two networks are directly connected to the cluster, Jumphost is in Net-A, CP-MGMT Interface is in Net-B. The cluster members can ping themselves over the sync and Monitored-Interfaces, but SSH is not possible. We got several customers with ClusterXL and I never experienced that before.
As soon as you reboot the active node, you need to wait ~15 seconds, and then the secondary is reachable.
And regarding R80.30: We got so many issues when going to R80.20, so I will use the oldest still supported software, to avoid problems. E.g. for Endpoint on R80.30 there were a few interesting posts in Checkmates, which doesn't provide trust in the version yet.
Best Regards
Johannes
the problem with accessing the standby over VPN is known and I stopped looking for a solution after hearing several times, it's expected behavior. All my customers with IPSec VPNs between corporate sites will get another vendor, who's firewall are able to be monitored by a VPN-remote system. I found a temporary solution by using a dummy-nat construction, but from time to time, the solution doesn't work anymore and we receive monitoring alerts again .... so it's expected behavior and Check Point will not be sold to these kind of customers.
In this case, the problem is without VPN, two networks are directly connected to the cluster, Jumphost is in Net-A, CP-MGMT Interface is in Net-B. The cluster members can ping themselves over the sync and Monitored-Interfaces, but SSH is not possible. We got several customers with ClusterXL and I never experienced that before.
As soon as you reboot the active node, you need to wait ~15 seconds, and then the secondary is reachable.
And regarding R80.30: We got so many issues when going to R80.20, so I will use the oldest still supported software, to avoid problems. E.g. for Endpoint on R80.30 there were a few interesting posts in Checkmates, which doesn't provide trust in the version yet.
Best Regards
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A short update
yesterday I deployed r80.30 ongoing take 71 which seems to have solved the issue though the PTJ-1657 does not be listed as an issue fixed in the take.
Best Regards
Kim
Kim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
I got the same issue accessing standby cluster member from non-local network. I did "ctl set int fwha_forw_packet_to_not_active 1" and now "fw ctl zdebug drop" shows "dropped by fwha_forw_flush_callback Reason: Successfully forwarded to other member" when I'm trying to reach second node via ssh. However, I see no packets at second node.
Any ideas?
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 17 | |
| 12 | |
| 5 | |
| 5 | |
| 5 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |
Upcoming Events
Thu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldFri 09 Jan 2026 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 42: Looking back & forwardThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 12 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 3: Exposing AI Vulnerabilities: CP<R> Latest Security FindingsThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldFri 09 Jan 2026 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 42: Looking back & forwardThu 22 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 2: Hacking with AI: The Dark Side of InnovationThu 26 Feb 2026 @ 05:00 PM (CET)
AI Security Masters Session 4: Powering Prevention: The AI Driving Check Point’s ThreatCloudAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter