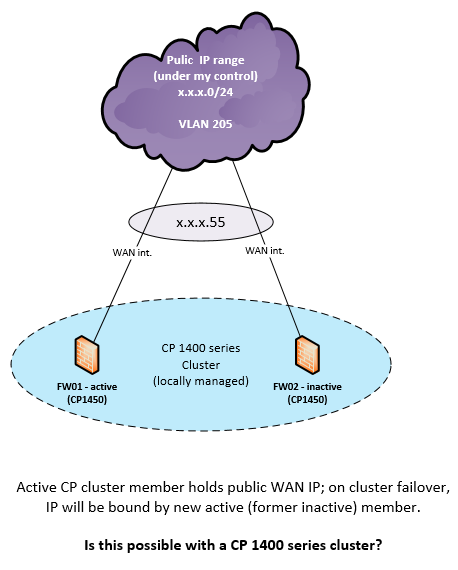
Hello folks,
I finally found some time to lab this again. Once the cluster is formed, it's pretty obvious what's happening:
10.161.91.251 primary node, physical
10.161.91.252 secondary node, physical
10.161.91.254 clusterxl virtual IP
Assuming 10.161.91.252 holds active role (master node that presents configuration etc):
- 10.161.91.251 is always responding to ping
- 10.161.91.252 responds to ping for approx. 30 sec, than stops responding
- 10.161.91.254 starts responding, responds for approx. 30 sec, than stops
- 10.161.91.252 starts responding again and so on
These 30 sec suggest that this has something to do with mac aging on the switch. (LAN interfaces terminate on a switch in a VLAN). However, setting mac aging to 10s on the switch does not lead to a shortened interval for "flapping" of the responding address.
I have already tried to stick all MAC-addresses I can see to both ports connecting to the primary and secondary member.
mac address-table static 0100.5e7f.fffa vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0100.5e00.0016 vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 001c.7f7e.6f78 vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 001c.7f7c.e19d vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0100.5e00.00fb vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0100.5e00.00fc vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0000.0000.fe00 vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0000.0000.fe01 vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0100.5e5A.0A64 vlan 1 interface FastEthernet0/2 FastEthernet0/1
mac address-table static 0100.5e28.0A64 vlan 1 interface FastEthernet0/2 FastEthernet0/1
I also disabled igmp snooping globally on the switch & set CCP to unicast instead of multicast. None of this changed this behaviour. There is currently no other layer 3 devices involved expect of the CheckPoints and my client host.
The switch has layer 3 capabilities (Catalyst 2960 for testing), but no IP interfaces in VLAN 1, where the LAN-interfaces of the cluster are placed.
Is this a lead to follow? Do you have any ideas on this?
As always, thanks in advance for your time and feedback!
/edit: The sync interfaces are directly connected with a straight patch cable.