- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
AI Security Masters E7:
How CPR Broke ChatGPT's Isolation and What It Means for You
Blueprint Architecture for Securing
The AI Factory & AI Data Center
Call For Papers
Your Expertise. Our Stage
Good, Better, Best:
Prioritizing Defenses Against Credential Abuse
Ink Dragon: A Major Nation-State Campaign
Watch HereCheckMates Go:
CheckMates Fest
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- General Topics
- :
- Re: Gateway Cluster Hardware Upgrade
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gateway Cluster Hardware Upgrade
I am upgrading the hardware of a cluster made of two open server gateways. The manager has a license of 10 gateways and it manages 10 gateways.
Is it possible to have a cluster made up of two gateways with different hardware?
So what process would you recommend for the migration?
I was thinking three options:
1) shutdown one of the old gateways and connect one of the new gateways with the configuration of the old gateway, establish SIC, push policies and failover. Finally repeat the process for the second old gateway.
Is this possible as we will have a cluster made up of gateways with different hardware?
2) Add the 2 new gateways with new ip address (the cluster will be made up of 4 gateways at this stage) , failover to them and shutdown the old gateways.
Is it possible, as we will have 12 gateways and we have a license only for 10 gateways.
3) shutdown the old gateways. Connect the new gateways, establish the SIC, push the policies.
This is the less preferred procedure as it will require outage.
31 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can ask CP for temporary licenses that will allow you to manage more gateways. I am sure they will accommodate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would go with option 1. Depending on the release you are running you actually can achieve seamless upgrade. Check for "ClusterXL upgrade methods and paths" sk107042.
HW wise (assuming you are on fairly recent SW release like R77.30 or R80.10) - it all depends on if you use CoreXL. If you do and are changing number of FWK instances then connection sync is not possible. Also you have to take care of interface naming (if you use open servers, you can keep the same interface names making life easier)
The easiest is to keep the same SW level with new members but it is also possible to upgrade to newer version during the process fairly seamlessly with latest SW releases
We have gone from appliances to chassis, VSX gateway (downgrading from R77.30 > R76) with a single ping packet loss
Too many questions to give you exact answer ![]() but it's not complicated
but it's not complicated
Good luck!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
One comment that I forgot - you can allow "out of state" connections for cutover time - this way you can minimise the outage. Once you have built the second member and just before pushing policy set to allow OOS connections. Then the failover to the new member will be less noticeable. Then re-instate it by pushing policy again once running on the new firewall.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here are the steps, not in absolute detail but gives enough to tweak them to your requirements. They have been tested these on four different clusters HW+SW upgrades with one ping loss.
Assumption is that interface names do not change and you use the same physical cables to the switches! You will need to take extra steps to amend those if they do. I have excluded obvious steps like backups
Preparation:
- Pre-build both new firewalls with exact OS configuration as old (routes, interfaces, users, backups, DNS. NTP etc)
Start of the upgrade:
- Disable stateful inspection in global properties to allow “out of state” connections during cutover. Connections cannot be synchronized if CoreXL is changing
- Set “maintain current active member” on ClusterXL tab cluster object if set otherwise
- Un-tick the box to push policy to both members (allow only one to succeed) – this is needed when we change SW version on the member
- Push policy to both existing firewalls
FW2 upgrade:
- cpstop OLDFW2 (do not shutdown as it's easier to roll back with cpstart)
- connect cables from OLDFW2 to NEWFW2
- establish SIC to NEWFW2
- Change SW version in the cluster object
- Push policy, it only should succeed to NEWFW2 (old has different SW version)
- Do you final checks throughput / connections / ping through FW etc of your choice (we run scripts to collect that)
- cphaprob stat state should be Ready on the NEWFW2
- Failover to the new firewall by cpstop on OLDFW1
- Check that NEWFW2 becomes active cphaprob stat
- Do your testing now
FW1 upgrade:
- Connect all cables from OLDFW1 (that's in cpstop state) firewall to NEWFW1
- Establish SIC to the NEWFW1
- Push policy and make sure it works on both cluster member now
- cphaprob stat state should become Standby on the new firewall NEWFW1
- Failover to the new firewall by clusterXL_admin down on NEWFW2
- Check that NEWFW1 becomes active cphaprob stat
- Do your checks again
- Re-enable ClusterXL on NEWFW2 by clusterXL_admin up
Finalise:
- Enable stateful inspection again in global properties (turn off allowing out of state)
- Reset cluster object ClusterXL active member to the original setting
- Set to push policy to both cluster members
- Push policy
- Check and update licenses in SmartUpdate
Check sim affinity for SecureXL
And that's it - go and enjoy your beer! ![]()
ROLLBACK
Connect all cables back to old firewalls.
Connect with SSH and run cpstart on both
Enable stateful inspection again in global properties.
Reset cluster object ClusterXL active member to the original setting
Set to push policy to both cluster members
Check and update appliance version in GUI
Push policy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Kaspars, I hadn't thought of the OOS. Good idea.
I was thinking about your vsx implementation. I was how would you design the network interfaces. In a checkpoint cluster you typically have three separate type of interfaces: cluster interfaces, non-monitored private interfaces and sync interfaces.
Did you keep these interfaces separated in a VSX invironment where you have your VSX gateway in two separated physical boxes? I guess that in a VSX environment it is still a good idea to have separated physical interfaces for syn, cluster and non-monitor (mgmt) if it is possible
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Luis, I'm not entirely sure if I understood your question about VSX. Typically I have slightly different approach with VSX HW+SW upgrades:
LAB part
- Change VSLS to run all VS active on one box vsx_util vsls, set VSX2 with higher priority (it's needed later so box does not failover back to VSX1)
- I would have MDS (management) replica in lab environment - do datafreeze in production and restore production MDS data in the lab
- Pre-build new VSX gateways with physical interfaces and other OS settings as required
- Upgrade / change VSX object version using vsx_util upgrade if you are changing gateway SW version
- Change interface names using vsx_util change_interfaces on MDS if required
- Push out VSX config using vsx_util reconfigure
- Verify licenses
- Change CoreXL if required
- Depending on your VSX environment set to allow OOS in all policies if CoreXL has changed
- Now your two new boxes are fully pre-configured!
- Create MDS backup in the lab
- Rack new VSX gateways in production racks and power on (no cables)
PROD part
- Restore MDS backup from lab to prod (at this point you will lose control over your VSX cluster)
- cpstop VSX2, and move all cables to NEWVSX2
- Test SIC (should b working) and make sure all VSes are trusted. NEWVSX2 will be in READY state
- Do hard cutover by cpstop VSX1
- Connections should work as you have OOS allowed
- Do your checks on NEWVSX2
- Now move cables to NEWVSX1
- Test SIC (should b working) and make sure all VSes are trusted. NEWVSX1 should be in STANDBY state
- Do hard cutover by cpstop NEWVSX2
- Do your checks on NEWVSX1
- Re-enable NEWVSX2
- Check licenses
- Check logs
- Set VSX1 to have higher priority if needed
- Turn off OSS
ROLLBACK
- Cpstart and plug back old firewalls
- MDS restore prod MDS
That's to give you an idea of approach that I have been using for years now. I mean you will need a lot of small tweaks to handle your environment.
Again you can always PM me ![]()
Merry Xmas!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is about the network interfaces. With a physical appliance you would typically have dedicated interfaces for mgmt, for sync and then cluster interfaces with multiple vlans for data. I was wondering if you keep that design with dedicated interfaces or you end up with sync, mgmt and data on the same trunk in a VSX environment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kaspars, to sens you a PM I need you to follow me. 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kaspars,
We don't have a LAB environment and we are planning on upgrading our VSX cluster from 77.20 to R77.30. However, we also need to replace the CP 4200 GW appliances with 4800's. We have bonding (bond0) configured with interfaces that have different names between 4200 and 4800. We are running MDS R80.10 and I was thinking:
- In production, move all VS's to OLDGW2 using vsx_util vsls
- In R80.10 SmartConsole, add a new Bond (bond1)
- From MDS, run vsx_util change_interfaces and select to " 2. Apply changes to the management database only"
- Select to replace bond0 with bond1
- setup the new 4800 GW's with R77.30 with bond1 including the new interfaces in the bond.
- Upgrade VSX Cluster via vsx_util upgrade in MDS to R77.30
- disconnect OLDGW1 and connect NEWGW1 with same Mgmt, sync IP and the new bond1 interfaces
- Run vsx_util reconfigure and select to reconfigure OLDGW1 (but NEWGW1 is physically connected)
- Disable OOS, push cluster policy to one gateway.
- Perform a hard cutover, check traffic
- Disconnect OLDGW2 and replace with NEWGW2 with R77.30
- Perform a vsx_util reconfigure on OLDGW2 (but NEWGW2 is physically connected)
- Push policy on both and perform vsls to distribute the VS's to different firewalls.
My main concern is the bond that needs to be replaced with another bond that has different interface names between the two appliances.
George
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually it's easier than that if the only interfaces in use are Mgmt, Sync and bond0 (being the only production interface)
You don't need to rename it as part of upgrade as management server does not care what interface names forms the bond. For example:
OLDGW: bond0 = eth1+eth2
NEWGW: bond0 = eth1-01 + eth1-02
you don't need need to worry about eth1 > eth1-01 and eth2 > eth1-02 change as that's invisible to VSX object, it only "sees" bond0 ![]()
Otherwise it should work! Good luck
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Aaaah,
So just remove the interfaces that do not reflect the new GW and add those that are missing then do a vsx_util reconfigure.
Can I do cphacu start to move traffic over or just do a cpstop on the old GW and traffic should failover to the new GW?
George Dellota
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
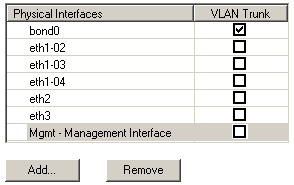
Not too sure if I understood you correctly so might be easier if you sent a screenshot of your VSX object physical interfaces.
For example here

if interface names inside bond1 and bond2 changed on the new appliance, it would not matter. Don't need any special steps during upgrade (vsx_util change_interfaces)
But it would matter if eth2-0x interface names changed, then you would run vsx_util change_interfaces just as you described.
BTW, I haven't had time to dig into it, but for us we had to run vsx_util change_interfaces command on the same interface twice, despite the fact it said execution completed successfully first time round. I discovered it accidentally by searching for old interface name after I run command first time and found some references still present in the DB. Running command second time actually "fixes" it. I wish I had an answer for it. It even says the second time that previous run has not fully completed - do you want to complete, answer yes.
Just remember to back up your mgmt before you start for easy rollback! ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Okay, I understand what you mean about the interfaces within bond0. So this is how our current 4200 appliance interfaces looks like:
When I replace the cluster with a 4800, I’ll configure each GW with bond0 and add eth1 and eth2.
I would have to do a vsx_util change_interfaces(twice) to delete eth1-02, eth1-03 and eth1-04 and add new interfaces eth4-eth7 and then do a vsx_util reconfigure to “sync” the MDS and GW settings.
I uncheck “Drop out of state TCP packets” in the global properties before the swap of OLDGW2
Do a hard cut on the running OLDGW2 and traffic (hopefully) fails over to NEWGW1 and redo the previous steps on NEWGW2.
Sounds about right?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
sounds about right! ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Kaspars plan seems very solid. Just a quick question if you swap out a Check Point cluster with an open server, what happens with the interfaces? Your active member will stay original as its the old Check Point device, when you click get interface to get the new interface configuration from the Open server it will be different for your active/standby members. Is it fine to temporarily have different interfaces in smartdashboard?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Opal,
If you replace a 12600 with a Check Point Open Server the interfaces names of the two appliances might be different for example the Check Point might use modules eth1-01 / eth3-02 etc. What will happen mid way through when you install the new standby, move cables from existing cluter eth1-01 to eth3(openserver), establish SIC. When you now go into topology table and "get interfaces" will it fetch the new eth3? This will also now mismatched to the active member.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Clustering is only supported with identical hardware.
You should be able to get a temporary license from either UserCenter or your Check Point SE to support the management of additional gateways.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Dameon,
absolutely it makes sense to support clustering only with identical hardware. But what about when the open server require a hardware upgrade? I guess that checkpoint supports or it should support at least one procedure, right? Is there any other procedure that checkpoint would recommend?
1) may not be ideal but I haven't being able to come up with anything better. I think that 1) may be better in terms of minimizing the service outage and also providing a easy/quick rollback if required.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sync won't work (or could potentially have unexpected behavior) unless the CPUs in the different systems are identical.
Assuming they are different, then the only way to swap things out with minimal disruption is to temporary disable the "Drop Out of State" options before the gateways are physically swapped.
You would disable this before swapping and leave it set for maybe 24 hours afterwords to allow long-standing connections to re-establish.
Similar to the following thread on CPUG: Zero downtime upgrade?
Note: This setting is not recommended long-term as this reduces the overall security of your gateways.
For TCP/ICMP, they are set in the Global Properties as shown below.
For UDP, refer to the following SK (note it's an "Expert" level SK, so you may not have access): How to configure the Security Gateway to drop Out of State UDP packets

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, Daemon
R80.10 is not described in Version of the SK.
Is this solution available in R80.10, too?
Takumi,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It should work the same in R80.10
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you.
I am glad if you can add it to this sk.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You're welcome to leave feedback on the SK to this effect.
I did spot check this particular Global Property is available via guidbedit in R80.10 (fw_drop_out_of_state_udp).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you.
I will try it.
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Resurrecting this thread to ask a question:
Can you say if zero downtime upgrade would be possible for R80.30 13500 to 15400 cluster appliance only migration. Both seem to show 16 cores when using cpview.
Also referencing the solution provided in thread below I ask if you could clarify the procedure for minimal downtime.
Thanks.
RS
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Phoneboy,
is this still valid?
i mean, hardware replacement between devices with same CPUs will handle the failover from old to new hardware with no disruption like normal Cluster Failover? other question, "same CPU" you mean number of core or number of CoreXL/SecureXL ?
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ClusterXL is only supported with identical hardware for all customer members.
It may work in situations where the hardware is "close enough" (same core count and snd/worker config).
This is not guaranteed and hasn't changed.
The alternate method I described changing the "out of state" configuration is not foolproof...and comes with a security risk.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I guess the same applies to different generation of the same platform? For example Proliant DL360 GEN9 to GEN 10 ? or ibm x650 m4 to m5?
Same core count and different processors can lead to unexpected behavior, right?
So better to go for minimum downtime than MultiVersion Cluster?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, it applies there as well.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 9 | |
| 8 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 2 |
Upcoming Events
Tue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementTue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFTue 12 May 2026 @ 10:00 AM (CEST)
The Cloud Architects Series: Check Point Cloud Firewall delivered as a serviceThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

{kind=link}
{kind=link}
{kind=link}
©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter