- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
On-Premise SD-WAN Management
Register HereWhat's New in R82.10?
Watch Here AI Security Masters E8:
Claude Mythos: New Era in Cyber Security
CheckMates Go:
The Moment Before
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- General Topics
- :
- How does the Medium Path (PXL) and Content Inspect...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How does the Medium Path (PXL) and Content Inspection work with R80

What is the exact processing of the flow with CoreXL and SecureXL? How are the packages processed here?
Q: Why this question?
A: There are several articles in the forum that currently discuss this thema.
References to the articles:
Check Point Threat Prevention Packet Flow and Architecture - 09-04-2017 (Moti Sagey )
R80.x Security Gateway Architecture (Logical Packet Flow) - 07-28-2018 ( Heiko Ankenbrand )
Simplified Packet Flow document - 08-06-2018 ( Valeri Loukine )
Security Gateway Packet Flow and Acceleration - with Diagrams - 08-06.2018 (Valeri Loukine )
References to SK's:
To avoid confusing all users, I think we should clarify this in this article.
Thanks in advance
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
33 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Heiko Ankenbrand, I love the sketch. Apparently you are not only a talented engineer but also a gifted artist. Do you have it in a good resolution?
Now, to your question.
SecureXL is the acceleration technology Check Point developed to speed up stateful inspection of authorized connections (packet acceleration) and, in some cases, opening new connections by bypassing slower FW kernel inspection.
CoreXL is an add-on that allows utilizing multiple cores for FW processing. It removes a critical FW kernel inspection limitation. By design and because of the nature of kernel memory utilization, a specific connection flow can only be inspected by a single CPU core. CoreXL adds a decision point (SND) allowing sticky static load balancing by designating particular connections to different CPU cores. This decision is being made by SND on the first packet arrival and is based on specific parameters (IPs and ports).
For that specific reason Check Point does not put CoreXL decision point on the packet flow diagram. To do so in a correct, you would have to multiply FW path sections per CPU and put the decision on top of everything, including SecureXL path. Such diagram would be too confusing and impractical to use.
As an add-on, CoreXL is only effective in tackling traffic with many different sources and destinations. In a rare case where there is only one source and one destination, the flow will hit a single core all the time, and the single core FW kernel bottleneck will still be unavoidable.
I have already answered this question in https://community.checkpoint.com/docs/DOC-3061-security-gateway-packet-flow-and-acceleration-with-di...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for the praise and thank you for the explanation. My little daughter helped me to colored the article picture. I can't do this so well🙂
I agree with you on all counts with one small exception. I have been working with Check Point since about 1998 and have seen all versions since version 3. I have seen a lot of pictures and illustrations on the topic, which try to map the problem with SecureXL, CoreXL and even ClusterXL (see Googel pictures).
What I haven't found in the past is an overview of everything. Many users who are new to Check Point products have the problem to understand the context clearly.
My idea was to create an overview that describes both worlds. Therefore I tried to unite both worlds in one overview during my vacation (about 24 hours) R80.x Security Gateway Architecture (Logical Packet Flow) .
Since there are both worlds (SecureXL and CoreXL), there must also be a way to map them schematically.
I hand the ball over to you or Check Point! Do you have an overview that describes this or can we do it together in the Checkmates forum.
I think this is extremely important for all checkmates and all other Check Point users.
That would be the challenge for everyone here.
Regards
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Now, I do need this picture in high res, please. We will print it out and put on the wall at Check Point. No kidding
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As for the matter, we do have plenty of diagrams for CoreXL and packet flows. The issue is, CoreXL decision is made per connection and then maintained per packet. For that reason, it is impossible to put it into packet based diagram. It is just a different dimension. If we agree on this point, everything else fits into place perfectly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Give use a A0 (Europe's largest paper format) diagram.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unless we don't need to make sense out of it later on, that's hardly a solution 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> As an add-on, CoreXL is only effective in tackling traffic with many different sources and destinations. In a rare case where there is only one source and one destination, the flow will hit a single core all the time, and the single core FW kernel bottleneck will still be unavoidable.
This statement is true by default on R77.30, however the Dynamic Dispatcher can be enabled to more evenly balance traffic load amongst the Firewall Workers based on their load. Note that a single "elephant flow" connection can still fully saturate a single Firewall Worker, but new connections will "run away" from the saturated core. In addition once a worker core is fully saturated Priority Queuing becomes active to ensure various "control" traffic like routing updates, SSH sessions, etc are processed in a timely fashion. The Dynamic Dispatcher is not enabled by default on R80.10+ gateway and later. sk105261: CoreXL Dynamic Dispatcher in R77.30 / R80.10 and above
Also the recent charts created by Heiko Ankenbrand are great and have inevitably led to a discussion of the Medium Path (PXL) inner workings. When writing my book I noticed that there was very little documentation about the Medium Path beyond the fact that it was there, and that it implements PSL for the various "Deep Inspection" blades like APCL and Threat Prevention. When asked in class about the difference between PXL and F2F, I would (somewhat inaccurately) gloss over PXL/PSL as an "optimized, shortened sequence of chain modules" whereas traffic going F2F/CPAS would pass through all chain modules as shown by fw ctl chain.
Not to rain on everyone's parade as these discussions are great, but there are big changes coming to the Medium Path and SecureXL in R80.20 that can be summarized with this screenshot:
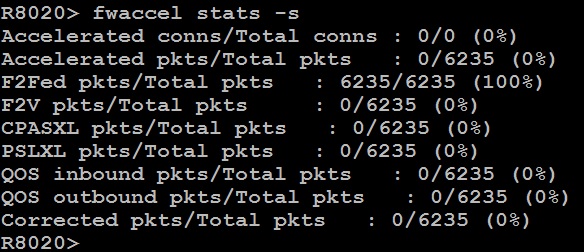
It would seem that the Medium Path has been broken up into several new paths that are being tracked separately, which makes my designation of process space on the firewall as the "fourth path" in the second edition of my book particularly unfortunate. Still in the process of working out all the SecureXL changes for R80.20 that were probably undertaken to support the new Falcon accelerator cards and updated kernel; the R80.20 addendum for my book is looking like it is going to be quite lengthy...
--
Second Edition of my "Max Power" Firewall Book
Now Available at http://www.maxpowerfirewalls.com
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
> Note that a single "elephant flow" connection can still fully saturate a single Firewall Worker
Yes, Timothy Hall that was what I meant. Say you open a single iperf flow, you hit the same CPU.
And thanks for mentioning Medium Path, that's a tough one. I can see here PSLXL and CPASXL that are both two different ways of streaming, both belonging to the Medium Path.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Timothy,
Yes, it has been an interesting process in the last few days and nights to reproduce everything correctly in the flowchart. Thanks again to Valeri Loukine , because he supports me well. But all in all, after 20 years of Check Point Firewall, I have once again dealt with the subject in depth. Yes, I also noticed that there are differences between R77.30, R80.10 and R80.20EA by SecureXL. I think we can take a closer look here soon.
Regards
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No problem sir, we are here to help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And by the way, Medium Path works exactly the same way in R80 as in R77 and below.
DeletedUser
Not applicable
2018-08-08
09:29 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great discussion. There are also subtle differences between R77.30 and R80.10 that are difficult to capture in a flow chart. For instance, in general, in R80.10 there is less reliance on INSPECT handlers which would logically follow the F2F path. This is covered in Services, Applications and Logs in Sync in the Unified Policy, but summarized below. When cloned and matched by protocol signature, then these would be handled by the CMI and Pattern Matcher signatures.
In R77 with separate policies for firewall and Application Control & URL Filtering there are Services Objects for the firewall policy and Network Service applications for the Application Control policy. In R80.10 this duplication is eliminated and the number of protocol handlers available in the advanced settings for the firewall service objects is reduced from over 200 to less than 20. In its place the default is to match by port in the service object and as an option to clone the service object and enable match by protocol signature.
P.S. also would like a higher resolution of that picture for my cube 😉
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not only that, Bob Bent
In R80.X FW Kernel has a new logical debug module called UP which does most of the heavy lifting for policy inspection and rule matching and only returns the match decision to old classic fw. Not to mention rulebase matching logic changed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Heiko, you can try labeling this image, as it allows for a better spacial perception of the traffic flows using different paths:

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
lol
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How about this pic, Heiko Ankenbrand? Can we have it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is changed ![]()
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is not what I was asking for. I was asking for your pencil sketch in hi res.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I send you pencil sketch in hi res per email this evening.
For all those who don't understand the background here. The original picture of this article was of me and my little daughter. She helped color this.

Regards,
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Timothy Hall has raised an interesting point (fw ctl chain).
A very important point in "fw ctl chain" is the following. Very little is mentioned in the documentaries and forums. I find this point very important when considering and debugging.
It describes the flow through the chain for specific packages:
(00000001) new processed flows
(00000002) previous processed flows
(00000003) ciphered traffic
(ffffffff) Everything
See Picture from fw ctl chain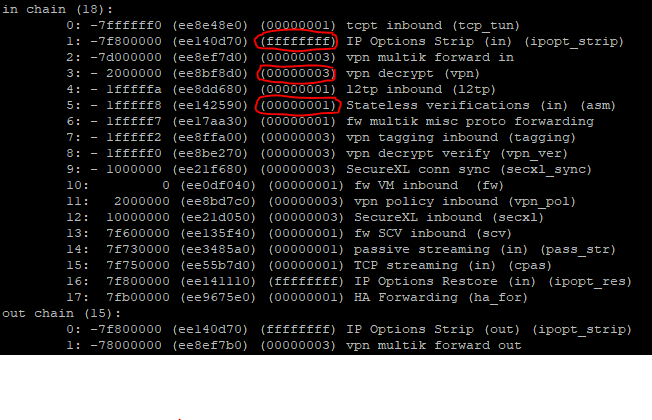
I look more and more closely here while debugging.
My question is, can something be used here to make statements about PXL for example "(00000002) previous processed flow"?
Or is my thinking wrong!
What I noticed is that I no longer see the parameter (00000002) for R80 in the chain. But it can also be a coincidence:-)
If necessary we should do this independently in another article to understand the depth here.
Regards
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, markings 00000002 are for those chains that are working in a "wire" mode. Indeed the chain wire_vm is not loaded in your case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Different approach!
One of my favorite commands is "fw ctl zdebug" and I also wrote an article about it here "fw ctl zdebug" Helpful Command Combinations.
Is it possible to make the PXL Connections visible? My idea is to use the following command and adjust it with grep,... if necessary:
fw ctl zdebug + all
Regards,
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You probably heard about my position towards zdebug, lol
When talking about fw ctl debug in general, you may try to touch debug modules such as CPAS, CI, APPI, etc. To start with, use Kernel Debug as a reference.
I am not sure that would be a sensible effort though. Those modules can yield lots of messages, and it is not obvious which particular debug modules to call in a general case with many features enabled.
And definitely, with lots of messages zdebug does not have a buffer big enough to catch all.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
One more reference. If you are looking for full fe debug modules and flags list; here it is: http://downloads.checkpoint.com/dc/download.htm?ID=56864
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I know I've been out of the loop for a bit but would it be appropriate to include cpmq (aka multiqueue) into this diagram?
And disucussion in regards to sim affinity etc would delve into the realm of actual core balance and tuning.
But recognizing that cpmq is a component of SXL and used extensively on the 64k chassis. As 10GbE becomes more common this are will need to be documented as well.
Just a thought...
-src
Sean Costello
Network Security Professional
SRC & Associates
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sean Costello there is always a question of how complex you want your diagram to be.
CPMQ (and SND, but this is an argument for another day) could only be on the diagram if you want to show the flow per CPU core. That would be a very interesting thing to do, but I am afraid, that would increase complexity of the diagram by two orders of magnitude.
I personally believe in simple things, especially when explaining complex subjects.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Agree with Valeri Loukine that adding Multi-Queue into the diagram would complicate it a bit too much. Even though Check Point has its hooks into MQ, it is mainly a function of the NIC driver itself, is not directly part of Check Point's code, and is really more part of Gaia/Linux. Once you step over that dividing line between Gaia/Linux and Check Point's code (INSPECT, SecureXL, etc) and try to further document the box labelled "Interface" in Heiko Ankenbrand's diagram, you open a big can of worms. In my book I cover this process in a section called "A millisecond in the life of a frame"; it glosses over a few esoteric areas and the ordering may not be 100% accurate but it provides sufficient background for tuning efforts:
1) Frame arrives at NIC hardware off the wire
2) Frame placed in NIC hardware buffer (no space? ++RX-OVR)
3) Hardware interrupt begin
4) Transfer frame to NIC driver via DMA for handling
5) NIC driver performs basic error checking (frame corrupt? ++RX-ERR)
6) Place frame in receive socket buffer (none available? no registered receiver? ++RX-DRP)
7) Place descriptor referencing location of frame in the proper ring buffer (there will be more than one of these per interface if MQ enabled)
8) Hardware interrupt end
some time later...
9) SoftIRQ run begins on SND/IRQ core
10) Process frames from ring buffer(s) and send to all registered receivers (i.e. SND, libpcap if tcpdump running)
11) Continue SoftIRQ run until all ring buffers are empty, maximum number of frames specified by net.core.netdev_budget (default 300) is reached, or two jiffies of time have elapsed
12) SoftIRQ run ends
And that was just the receive process for frames, didn't even get into the transmit process...
--
Second Edition of my "Max Power" Firewall Book
Now Available at http://www.maxpowerfirewalls.com
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I Agree with Valeri Loukine and Timothy Hall that adding Multi-Queue into the diagram would complicate it a bit too much.
I still have a lot of points to think of for the article R80.x Security Gateway Architecture (Logical Packet Flow) .
For example, several chain modules such as "tcpt Inbound", "IP Options Strip", "L2TP inbound", "IP Options Restore ",...
or for ClusterXL "HA Forwarding"
or SecureXL offloading for old SAM cards and new Falcon cards (Falcon Modules and R80.20)
and and and.
But eventually there will be too much in one drawing. Then the users lose the overview. These are also all old fonctions that already exist in R77.
I wanted to show new features that are only available since R80.10 and newer:
- new fw monitor inspection points for VPN (e and E)
- new MultiCore VPN
- UP Manager
- Content Awareness (CTNT)
There are also here still more functions other also that can go beyond the frame.
To the important topics like also Multi-Queue I have indicated the appropriate references.
If you want to go deeper, I recommend the book of Timothy Hall (see link: http://www.maxpowerfirewalls.com).
It is really very good and you can read many points that are discussed here. But now I no longer advertise Timothy's book:-)
Regards,
➜ CCSM Elite, CCME, CCTE, CCVS ➜ www.checkpoint.tips
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 12 | |
| 5 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |
Upcoming Events
Tue 14 Jul 2026 @ 10:00 AM (PDT)
AI Security Masters E11: READY OR NOT: Securing the AI Enterprise 3/5 - AI Workforce SecurityThu 30 Jul 2026 @ 10:00 AM (PDT)
AI Security Masters E12: READY OR NOT: Securing the AI Enterprise 4/5 - AI GatewayThu 20 Aug 2026 @ 10:00 AM (PDT)
AI Security Masters E13: READY OR NOT: Securing the AI Ent 5/5 - AI Research & Threat LandscapeTue 14 Jul 2026 @ 10:00 AM (PDT)
AI Security Masters E11: READY OR NOT: Securing the AI Enterprise 3/5 - AI Workforce SecurityThu 30 Jul 2026 @ 10:00 AM (PDT)
AI Security Masters E12: READY OR NOT: Securing the AI Enterprise 4/5 - AI GatewayThu 20 Aug 2026 @ 10:00 AM (PDT)
AI Security Masters E13: READY OR NOT: Securing the AI Ent 5/5 - AI Research & Threat LandscapeAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter