Thanks everyone for great information/discussion! 🙂
I was reading about HyperFlow which should be enabled on the 7000 Appliance and also supported on VSX but im unsure how it actually works if a VS only has one instance?
On the 5600 Appliances, 6 Virtual systems had total of 10 FWK instances/processes (4 of them have only 1 and the two others have 2 & 4) so basically 10 instances sharing 3 cores.
On the 7000`s it looks like the 10 instances each should get their own dedicated core (of the 14 (28 HT) available for Corexl) but I guess we could still potentially then
get an issue if a large connection hits just 1 VS?
With VSX/VS and HyperFlow, would this actually work for a VS with only 1 instance or would HyperFlow also require atleast 2 instances for the VS to work ?
All the VS`es are randomly failing over, complaining about loosing Sync/VLAN/Wrp-interfaces and not receiving CCP-packets and it doesnt happen at the same time for all VS`es
so we are definately not loosing network connectivity for the VLAN`s as the vswitches are used by multiple VS`es.
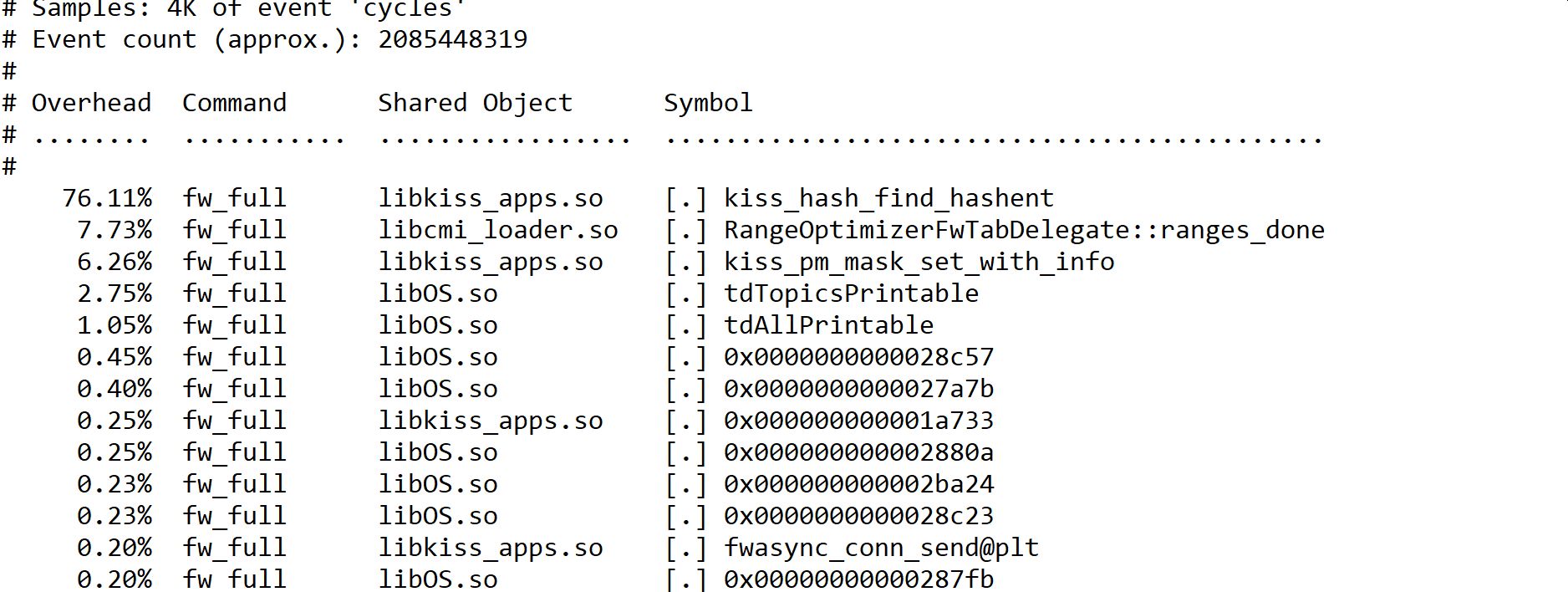
Prior to the failovers we usually (always) get these messages regarding "fw_full" and we have alot of "spike_detective" reports aswell;
###
Dec 11 11:37:48 2023 fw-vsxnode1 spike_detective: spike info: type: cpu, cpu core: 2, top consumer: fw_full, start time: 11/12/23 11:37:29, spike duration (sec): 18, initial cpu usage: 95, average cpu usage: 80, perf taken: 0
Dec 11 11:37:48 2023 fw-vsxnode1 spike_detective: spike info: type: thread, thread id: 1281, thread name: fw_full, start time: 11/12/23 11:37:35, spike duration (sec): 12, initial cpu usage: 99, average cpu usage: 80, perf taken: 0
Dec 11 11:38:49 2023 fw-vsxnode1 fwk: CLUS-110305-1: State change: ACTIVE -> ACTIVE(!) | Reason: Interface wrp768 is down (Cluster Control Protocol packets are not received)
Dec 11 11:38:51 2023 fw-vsxnode1 fwk: CLUS-114904-1: State change: ACTIVE(!) -> ACTIVE | Reason: Reason for ACTIVE! alert has been resolved
###'
Unfortunately the VS`es protects some critical infrastructure so any testing/patching requires maintenance windows and people on physical watch etc so testing stuff is a bit complicated here, but any tips/hints as to what could be the root cause here is very appreciated as we are unfortunately not getting much from TAC. I also added a screenshot from one of the spike-reports that frankly doesnt tell me much 🙂
We have a mix of blades running on different VS`es. One has IPS+ABOT+AV (no SMB/HTTP/FTP scanning), one only has IPS and the rest have IPS,ABOT,AV,URLF,APCL. They are all failing but at different frequencies.
CCSM / CCSE / CCVS / CCTE


{kind=link}