- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
10 December @ 5pm CET / 11am ET
Announcing Quantum R82.10!
Learn MoreOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
Maestro Madness
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Security Gateways
- :
- Re: VSX/VS instances - FWK instances with SMT/HT
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
VSX/VS instances - FWK instances with SMT/HT
Hello,
Have been trying to find some information about VS FWK/Instances when moving to new Appliances with HyperThreading. (5600>7000)
We were running VSX VSLS on R81.10 on 5600 Appliances with 6 VS’es and total number of instances 10. 5600 has 8 cores so we were «overbooked» but didnt have any issues.
We moved to R81.20 on 7000 Appliances (32 cores with hyperthreading. 16 physical) but did not change instances on VS’es.
Does this mean we have actually reduced the performance for the VS’es and should increase/double the amoumt of instances per VS or disable HyperThreading ?
A Core can handle traffic from multiple fwk processes, but can a fwk process send traffic to multiple cores?
We have cpu issues and failovers on VS’es after the upgrade of software/hardware and i cant seem to find any info/reccomendations regarding increase of instances/FWK when moving to Appliances with HyperThreading.
CCSM / CCSE / CCVS / CCTE
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Issues seems to have been finally resolved with T41 (and possibly also a reboot that put a missing kernel parameter that was in fwkern.conf but not in the OS)! Had a separate thread for the issues here for anyone interrested 🙂
Thanks to everyone that has posted in the thread, learned alot new stuff along the way 🙂
CCSM / CCSE / CCVS / CCTE
15 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By default, the worker threads aren't bound to particular virtual cores, so the OS scheduler is free to put them wherever. 10 worker threads scheduled on 16 real cores plus 16 hyperthreads will end up on real cores almost exclusively.
That said, I think your old core count is off. The 5600 runs a Core i5-4590S, which only has four cores in 65W and doesn't even have hyperthreading. The 5800 run a Xeon E3-1285L v4, which has four cores plus four hyperthreads in 65W. What processor does your 7000 have?
egrep "^model name" /proc/cpuinfo
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your reply! 🙂
You are of course correct, the 5600 Appliance has/had 4 cores and not 8, and 6 VS`es with 10 instances was running smoothly.
On 7000 Appliances with 16 cores (32 HT) we are having issues and TAC points to performance issues which then definately shouldnt be an issue if 10 fwk`s were sharing 4 cores on R81.10 but struggling on 16 cores if the 10 worker threads now get their own CPU-core if I understand correctly ?
On the 7000 i get the following CPU-model;
model name : Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You do need to consider the clockspeed of the CPU:s
Some workflows / traffic want higher clockspeeds and some want more cores to spread the traffic.
Based on the clockspeed of the Core i5 and the 4216 i would suggest you actually need to increase the core count on some of the VS.
Its same with like interfaces, as the cores are slower more of them are needed to manage high thruput.
The reason why you want many cores is that you can enable more blades and functions, but when it comes to pure performance on single threads you need high clockspeed.
Performance get more complicated on VSX and not all VS may use the performance the same time.
quick check the Core i5 have much higher clockspeed than the Xeon.
Core i5 is base 3.0Ghz turbo 3.7ghz
https://www.intel.com/content/www/us/en/products/sku/80816/intel-core-i54590s-processor-6m-cache-up-...
Xeon(R) Silver 4216, Base 2.1Ghz and Turbo 3.2Ghz
https://www.intel.com/content/www/us/en/products/sku/193394/intel-xeon-silver-4216-processor-22m-cac...
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the info and update!
It really does get a bit messy with VSX/VS 🙂
We actually never had a very high CPU-load when 6 VS`es and 10 instances shared a 4-core CPU but now with 14(28) cores
all virtual systems are failing over back/forth between Appliances at every random hour, even at times with very little traffic.
Before it fails we can see spike detective registering something in regards to "fw_full" and have a TAC-case for that issue.
Just talked with a collegue and they actually had to do a few R81.20 -> R81.10 rollback due to sudden CPU-increase, crashes, reboots and various strange issues that all was solved with a rollback.
Will definately consider allocating more cores aswell, but have a bad feeling about this version.
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The rule of thumb when it comes to VSX is upgrade after a release has HFA 100+ 🙂 So yes i would also go for R81.10 😉
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A VSX customer und me, we decided to go "Recommended minus one". That means, we will upgrade VSX to the release before the actual recommended version. So, when R82 will get recommended version we will upgrade to R81.20. We had very bad experiences when upgrading VSX to the actual recommended version for two times with massive problems and escalations. Maybe, that is nearly the same than a JHFA Take higher than 100. 😉
(We also decided to upgrade more often. The last upgrades were R77.30 to R80.30 and R80.30 to R81.10. The next upgrade will be R81.10 to R81.20. We hope that this will result in less things changing in code fundamentally.)
That said, we had nearly no problems with the recommended version and "normal" gateways and clusters. Just for the records.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
With modern Intel processors, clock speed (even turbo speed) doesn't matter as much as TDP per core. The i5-4590S in the 5600 is 65W for 4c4t, which comes out to 16.25W per core. Ten worker threads across four cores would mean each core handles an average of 2.5 threads. 16.25W per core over 2.5 threads per core comes out to about 6.5W per thread. The Xeon Silver 4216 in the 7000 is 100W for 16c32t, or 6.25W per core. Not that big a difference.
The 5600 would have a significant advantage in bursty traffic which hits only one VS. When the other VSs are mostly quiet, the VS experiencing a traffic burst would get closer to the 16.25W theoretical ideal per thread.
Bottom line, the processor alone doesn't explain the problem. The system has gone from severely core-constrained to having enough cores that it shouldn't be context-switching at all. Giving VSs more cores might help, but I doubt it.
As an aside, this is yet another reason I prefer open servers to Check Point's branded boxes: you can pick boxes with fewer, higher-power cores. From the same line of processors, a 4215R would have dramatically better performance: 130W into 8x16t, or 16.25W per core.
Is it swapping or anything? I've had a few production VSX clusters on R81.20 for 2-3 months with no trouble from any of them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Bob_Zimmerman this is some really great and thorough explanation! Modern CPUs and SoCs are getting very confusing, perhaps not as much on the enterprise side of things, but Check Point often ops for consumer-grade hardware in their lower series of appliances. You can put the same Intel Core i9-14900K into different chassis, and their performance might be very different depending on power and cooling. Not just based on throttling but also based on BIOS/UEFI, letting the CPU scale beyond their default TDP with sufficient power and cooling.
But to be frank, when opting for Check Point branded hardware, it really doesn't make any sense for a CPAP-SG5600 to outperform a CPAP-SG7000 with identical configuration. We can apply all kinds of logic to the equation, but from the customer point-of-view, it doesn't really matter at the end of things.
The big question in this specific scenario is whether this is indeed the hardware constraining the performance, or if this is a software related issue. Even-though the VSX configuration and deployment is identical, the software is not as the CPAP-SG5600 was running R81.10 with JHF XXX, while the CPAP-SG7000 is running R81.20 with JHF Take 26.
Reverting back to R81.10 is rather difficult as this is VSX. vsx_util downgrade specifically mentions that it cannot be done if there has been configuration changes after running vsx_util upgrade, and the move to new appliances means that there has been configuration changes with the move to R81.20.
Does this mean that "best-practice" when it comes to moving back to R81.10 would be to revert the management back to a snapshot from before running vsx_util upgrade to R81.20? This will put the entire management back several weeks, which of course is troublesome.
This will of course be a lot of work and trouble just to see if it the CPAP-SG7000 behaves any different running R81.10. Worst-case scenario would be for the performance and behaviour to be the same with R81.10. That would be a lot of time and effort for nothing.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Another thing when it comes to CPU performance is the underlying architecture. Intel Core i5-4590S is Haswell from 2013, and Intel Xeon Silver 4216 is Cascade Lake from 2019. The IPC and efficiency should be significantly improved. Running at the same frequencies, the Intel Xeon Silver 4216 should outperform Intel Core i5-4590S in almost every scenario with a solid margin. We are also comparing 22 nm with 14 nm. This also means DDR3 vs DDR4, etc.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The newer microarchitectures perform better per Watt, yes, but they focus on breadth at the cost of single-core performance. CoreXL is great at distributing connections across many available cores, but lots of low-power cores aren't good for fewer, larger flows. That's what I mean when I say bursty traffic which hits a single VS would perform noticeably better on the 5600. If the other VSs aren't competing for processor time, the 5600 has a lot more power to throw at the problem. Far more than the newer microarchitecture can compensate for.
The 7000 can handle a lot more flows. The 5600 is likely to have noticeably higher throughput for one or two flows unless you use HyperFlow (brand new in R81.20).
Now that I think about it, maybe something is going weird with HyperFlow on the 7000? I'm not sure how it interacts with VSX. Could be worth disabling it if it's running.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks everyone for great information/discussion! 🙂
I was reading about HyperFlow which should be enabled on the 7000 Appliance and also supported on VSX but im unsure how it actually works if a VS only has one instance?
On the 5600 Appliances, 6 Virtual systems had total of 10 FWK instances/processes (4 of them have only 1 and the two others have 2 & 4) so basically 10 instances sharing 3 cores.
On the 7000`s it looks like the 10 instances each should get their own dedicated core (of the 14 (28 HT) available for Corexl) but I guess we could still potentially then
get an issue if a large connection hits just 1 VS?
With VSX/VS and HyperFlow, would this actually work for a VS with only 1 instance or would HyperFlow also require atleast 2 instances for the VS to work ?
All the VS`es are randomly failing over, complaining about loosing Sync/VLAN/Wrp-interfaces and not receiving CCP-packets and it doesnt happen at the same time for all VS`es
so we are definately not loosing network connectivity for the VLAN`s as the vswitches are used by multiple VS`es.
Prior to the failovers we usually (always) get these messages regarding "fw_full" and we have alot of "spike_detective" reports aswell;
###
Dec 11 11:37:48 2023 fw-vsxnode1 spike_detective: spike info: type: cpu, cpu core: 2, top consumer: fw_full, start time: 11/12/23 11:37:29, spike duration (sec): 18, initial cpu usage: 95, average cpu usage: 80, perf taken: 0
Dec 11 11:37:48 2023 fw-vsxnode1 spike_detective: spike info: type: thread, thread id: 1281, thread name: fw_full, start time: 11/12/23 11:37:35, spike duration (sec): 12, initial cpu usage: 99, average cpu usage: 80, perf taken: 0
Dec 11 11:38:49 2023 fw-vsxnode1 fwk: CLUS-110305-1: State change: ACTIVE -> ACTIVE(!) | Reason: Interface wrp768 is down (Cluster Control Protocol packets are not received)
Dec 11 11:38:51 2023 fw-vsxnode1 fwk: CLUS-114904-1: State change: ACTIVE(!) -> ACTIVE | Reason: Reason for ACTIVE! alert has been resolved
###'
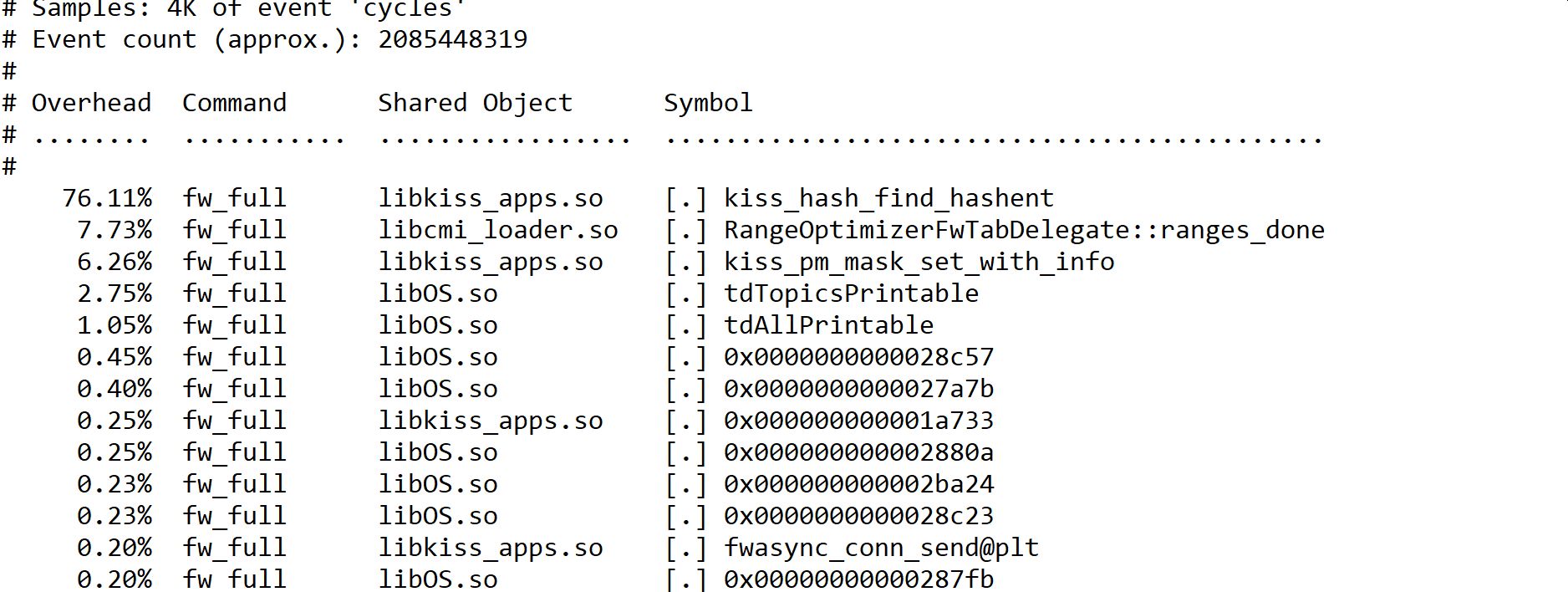
Unfortunately the VS`es protects some critical infrastructure so any testing/patching requires maintenance windows and people on physical watch etc so testing stuff is a bit complicated here, but any tips/hints as to what could be the root cause here is very appreciated as we are unfortunately not getting much from TAC. I also added a screenshot from one of the spike-reports that frankly doesnt tell me much 🙂
We have a mix of blades running on different VS`es. One has IPS+ABOT+AV (no SMB/HTTP/FTP scanning), one only has IPS and the rest have IPS,ABOT,AV,URLF,APCL. They are all failing but at different frequencies.
CCSM / CCSE / CCVS / CCTE
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@PetterD, regarding your questions on Hyperflow:
Hyperflow is a global feature and can handle traffic from any instance, even across different VSs.
It will trigger and start handling jobs (pattern matching, hash) upon detecting an elephant flow on an instance.
At the same time, it can still handle traffic from other instances (including in other VSs).
There isn’t a minimum requirement on instances per VS, it will work with a single-instance VS.
This behavior is consistent across all hardware that support Hyperflow.
To check if your GW had elephant flows in the last 24 hours, you can run “fw ctl multik print_heavy_conn”.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for the information regarding how VSX/VS and HyperFlow works!
Does it spawn additional FWK-processes in addition to (for instance the 1 instance) allocated to a specific VS ?
We have used the "heavy connections" output the last few days to gather information about a few specific hosts that generated alot of heavy (backup) traffic and used Fast Accellerator to avoid inspection/offload it in hopes of improving the situation.
Now we have very few high CPU-messages in the logs but the failovers keeps occuring pointing to loss of CCP-contact on Sync and various other WRP-interfaces. It doesnt seem to affect all VS`es at the same time which is strange considering they share the same vswitches so still suspect a bug in R81.20 T26 causing alot of headache. Cant find anything in T41 in regards to this but looking to get a maintenance window to check it out.
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Issues seems to have been finally resolved with T41 (and possibly also a reboot that put a missing kernel parameter that was in fwkern.conf but not in the OS)! Had a separate thread for the issues here for anyone interrested 🙂
Thanks to everyone that has posted in the thread, learned alot new stuff along the way 🙂
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm glad to hear your issue has been resolved 🙂
Regarding your Hyperflow question:
Hyperflow handles the instances’ traffic with its own dedicated process. It does not spawn additional FWK threads during runtime.
In general, the number of instances within a VS can only be changed via VS cpstop-cpstart.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 24 | |
| 20 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 | |
| 4 |
Upcoming Events
Fri 12 Dec 2025 @ 10:00 AM (CET)
Check Mates Live Netherlands: #41 AI & Multi Context ProtocolTue 16 Dec 2025 @ 05:00 PM (CET)
Under the Hood: CloudGuard Network Security for Oracle Cloud - Config and Autoscaling!Fri 12 Dec 2025 @ 10:00 AM (CET)
Check Mates Live Netherlands: #41 AI & Multi Context ProtocolTue 16 Dec 2025 @ 05:00 PM (CET)
Under the Hood: CloudGuard Network Security for Oracle Cloud - Config and Autoscaling!Thu 18 Dec 2025 @ 10:00 AM (CET)
Cloud Architect Series - Building a Hybrid Mesh Security Strategy across cloudsAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2025 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter