FW-OA-A> ver
Product version Check Point Gaia R80.30
OS build 200
OS kernel version 2.6.18-92cpx86_64
OS edition 64-bit
FW-OA-A> cpinfo -y all
This is Check Point CPinfo Build 914000196 for GAIA
[IDA]
No hotfixes..
[MGMT]
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
[CPFC]
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
[FW1]
HOTFIX_MAAS_TUNNEL_AUTOUPDATE
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
FW1 build number:
This is Check Point's software version R80.30 - Build 209
kernel: R80.30 - Build 216
[SecurePlatform]
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
[PPACK]
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
[CPinfo]
No hotfixes..
[DIAG]
No hotfixes..
[CVPN]
HOTFIX_R80_30_JUMBO_HF_MAIN Take: 219
[CPUpdates]
BUNDLE_HCP_AUTOUPDATE Take: 24
BUNDLE_INFRA_AUTOUPDATE Take: 39
BUNDLE_DEP_INSTALLER_AUTOUPDATE Take: 20
BUNDLE_MAAS_TUNNEL_AUTOUPDATE Take: 53
BUNDLE_R80_30_JUMBO_HF_MAIN Take: 219
[CPDepInst]
No hotfixes..
[AutoUpdater]
No hotfixes..
[hcp_wrapper]
HOTFIX_HCP_AUTOUPDATE
[Expert@FW-OA-A:0]# uname -a
Linux FW-OA-A 2.6.18-92cpx86_64 #1 SMP Tue Sep 8 20:04:48 IDT 2020 x86_64 x86_64 x86_64 GNU/Linux
A Message:
Mar 4 13:12:34 2021 FW-OA-A xpand[16114]: admin localhost t -volatile:configurationChange
Mar 4 13:12:35 2021 FW-OA-A xpand[16114]: admin localhost t -volatile:configurationSave
Mar 4 17:20:58 2021 FW-OA-A kernel: [fw4_1];CLUS-110305-1: State change: ACTIVE -> ACTIVE(!) | Reason: Interface eth1-01 is down (Cluster Control Protocol packets are not received)
Mar 4 17:20:59 2021 FW-OA-A kernel: [fw4_1];CLUS-114904-1: State change: ACTIVE(!) -> ACTIVE | Reason: Reason for ACTIVE! alert has been resolved
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_1];CLUS-110305-1: State change: ACTIVE -> ACTIVE(!) | Reason: Interface eth1-01 is down (Cluster Control Protocol packets are not received)
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_1];CLUS-110305-1: State change: ACTIVE! -> DOWN | Reason: Interface eth1-01 is down (Cluster Control Protocol packets are not received)
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_1];CLUS-214704-1: Remote member 2 (state STANDBY -> ACTIVE) | Reason: No other ACTIVE members have been found in the cluster
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_6];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_1];CLUS-114802-1: State change: DOWN -> STANDBY | Reason: There is already an ACTIVE member in the cluster (member 2)
Mar 4 17:21:07 2021 FW-OA-A kernel: [fw4_1];CLUS-100102-1: Failover member 1 -> member 2 | Reason: Interface eth1-01 is down (Cluster Control Protocol packets are not received)
Mar 4 17:21:08 2021 FW-OA-A kernel: [fw4_7];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:08 2021 FW-OA-A kernel: [fw4_2];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:08 2021 FW-OA-A kernel: [fw4_9];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:08 2021 FW-OA-A kernel: [fw4_3];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:09 2021 FW-OA-A kernel: [fw4_1];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:09 2021 FW-OA-A kernel: [fw4_5];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:11 2021 FW-OA-A kernel: [fw4_0];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:14 2021 FW-OA-A kernel: [fw4_8];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 17:21:14 2021 FW-OA-A kernel: [fw4_4];fwldbcast_handle_retrans_request: Updated bchosts_mask to 1
Mar 4 19:12:23 2021 FW-OA-A xpand[16114]: admin localhost t +installer:check_for_updates_last_res Last check for update is running
Mar 4 19:12:23 2021 FW-OA-A xpand[16114]: Configuration changed from localhost by user admin by the service dbset
Mar 4 19:12:23 2021 FW-OA-A xpand[16114]: admin localhost t +installer:update_status -1
B message:
Mar 4 12:16:35 2021 FW-OA-B xpand[19429]: admin localhost t -volatile:configurationChange
Mar 4 12:16:36 2021 FW-OA-B xpand[19429]: admin localhost t -volatile:configurationSave
Mar 4 17:21:07 2021 FW-OA-B kernel: [fw4_1];CLUS-210300-2: Remote member 1 (state ACTIVE -> DOWN) | Reason: Interface is down (Cluster Control Protocol packets are not received)
Mar 4 17:21:07 2021 FW-OA-B kernel: [fw4_1];CLUS-114704-2: State change: STANDBY -> ACTIVE | Reason: No other ACTIVE members have been found in the cluster
Mar 4 17:21:07 2021 FW-OA-B kernel: [fw4_1];CLUS-100102-2: Failover member 1 -> member 2 | Reason: Available on member 1
Mar 4 17:21:07 2021 FW-OA-B kernel: [fw4_1];CLUS-214802-2: Remote member 1 (state DOWN -> STANDBY) | Reason: There is already an ACTIVE member in the cluster
Mar 4 18:16:28 2021 FW-OA-B xpand[19429]: admin localhost t +installer:check_for_updates_last_res Last check for update is running
Mar 4 18:16:28 2021 FW-OA-B xpand[19429]: Configuration changed from localhost by user admin by the service dbset
Mar 4 18:16:28 2021 FW-OA-B xpand[19429]: admin localhost t +installer:update_status -1
Mar 4 18:16:28 2021 FW-OA-B xpand[19429]: Configuration changed from localhost by user admin by the service dbset
[Expert@FW-OA-A:0]# netstat -ni
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
Mgmt 1500 0 357107174 0 0 0 152432164 0 0 0 BMRU
Sync 1500 0 1140897383 0 0 0 1280037944 0 0 0 BMRU
eth1-01 1500 0 44660252890 0 0 0 73375428981 0 0 0 BMRU
eth1-02 1500 0 73378082535 0 0 0 44611246310 0 0 0 BMRU
lo 16436 0 2159425 0 0 0 2159425 0 0 0 LRU
[Expert@FW-OA-A:0]# cphaprob -a if
CCP mode: Automatic
Required interfaces: 4
Required secured interfaces: 1
Sync UP sync(secured), unicast
Mgmt UP non sync(non secured), unicast
eth1-01 UP non sync(non secured), unicast
eth1-02 UP non sync(non secured), unicast
Virtual cluster interfaces: 3
Mgmt 10.220.61.150 VMAC address: 00:1C:7F:00:0D:0C
eth1-01 172.20.251.4 VMAC address: 00:1C:7F:00:0D:0C
eth1-02 172.20.252.4 VMAC address: 00:1C:7F:00:0D:0C
[Expert@FW-OA-A:0]# cphaprob -l list
Built-in Devices:
Device Name: Interface Active Check
Current state: OK
Device Name: Recovery Delay
Current state: OK
Device Name: CoreXL Configuration
Current state: OK
Registered Devices:
Device Name: Fullsync
Registration number: 0
Timeout: none
Current state: OK
Time since last report: 3.83178e+06 sec
Device Name: Policy
Registration number: 1
Timeout: none
Current state: OK
Time since last report: 3.83178e+06 sec
Device Name: routed
Registration number: 2
Timeout: none
Current state: OK
Time since last report: 10701.3 sec
Device Name: fwd
Registration number: 3
Timeout: 30 sec
Current state: OK
Time since last report: 1.99742e+06 sec
Process Status: UP
Device Name: cphad
Registration number: 4
Timeout: 30 sec
Current state: OK
Time since last report: 1.99741e+06 sec
Process Status: UP
Device Name: Init
Registration number: 5
Timeout: none
Current state: OK
Time since last report: 1.9974e+06 sec
[Expert@FW-OA-A:0]#
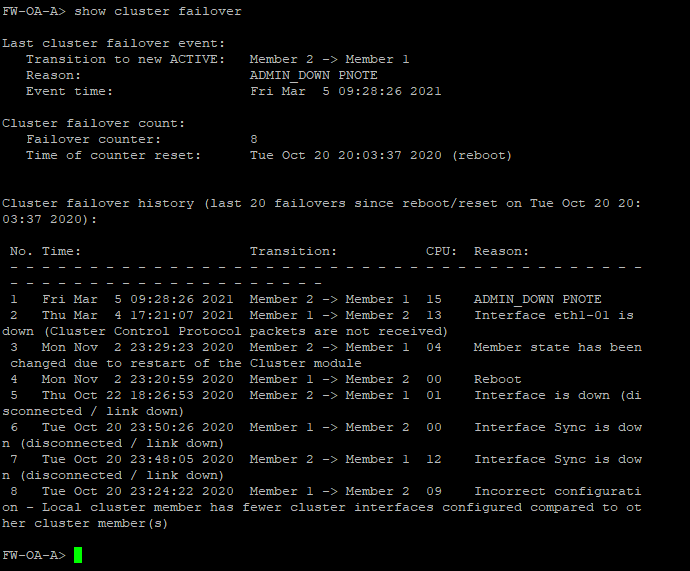
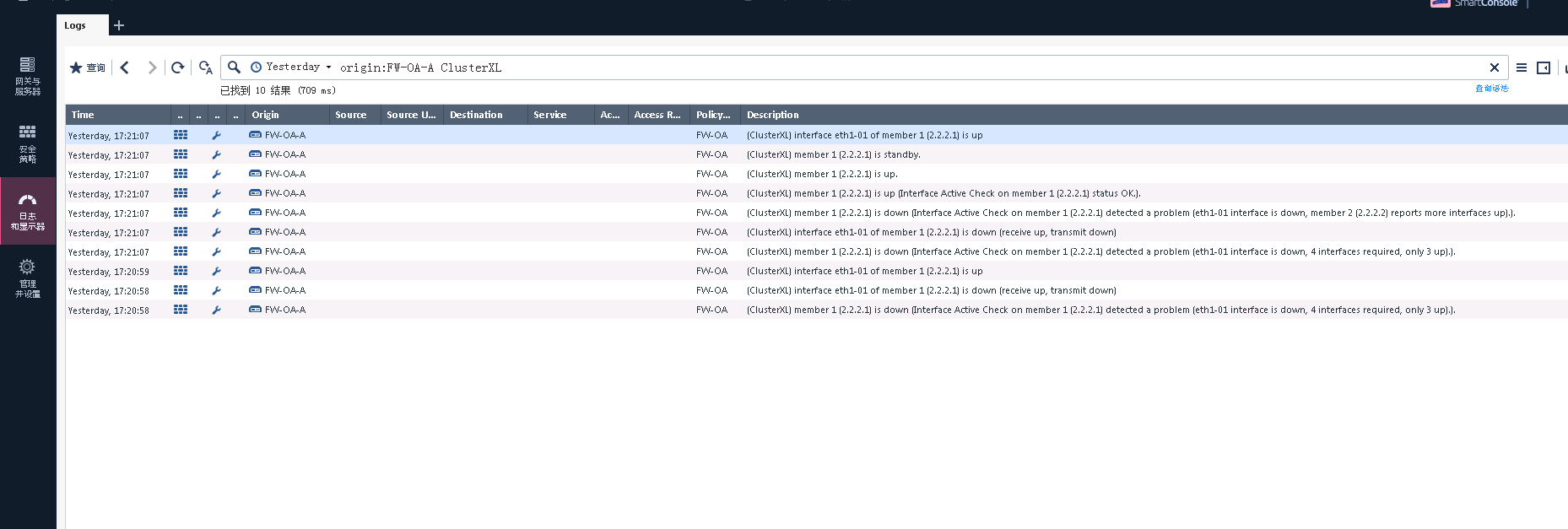
The client check switch direct interface is no any down records. Could you find the root cause of the failover issue?

{kind=link}
{kind=link}