- Products
Quantum
Secure the Network IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloudGuard CloudMates
Secure the Cloud CNAPP Cloud Network Security CloudGuard - WAF CloudMates General Talking Cloud Podcast Weekly Reports - Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
Maestro Masters
Round Table session with Maestro experts
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Quantum
- :
- Maestro Masters
- :
- Re: limitation "MAGG with LACP configuration is on...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
limitation "MAGG with LACP configuration is only supported in Chassis, not in Maestro" still exist ?
I'm not sure but this limitations still exists in R81.10? LACP not possible with management interfaces with Maestro?

.png")
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi is fully supported on R81.10 maestro and chassis.
Documentation will be updated soon
31 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi is fully supported on R81.10 maestro and chassis.
Documentation will be updated soon
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I did an installation of Maestro with R81.10 and used the latest JHF available at that time (66 I believe) and couldn't make it work for magg. The same configuration works perfect for the management ports of Maestro itself and downlinks but not for magg.
Forgot to mention - I talk about configuring magg and lacp for Cisco VPC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What kind of issues were you facing? I have a Maestro VSX environment running Dual-Site, Single-Orch, and it's behaving strangely. This is running R81.20 + JHF Take 24, so it should be supported.
We are seeing a ton of these messages in /var/log/messages on all Security Group members:
kernel:magg0: An illegal loopback occurred on adapter (eth1-Mgmt1)
kernel:Check the configuration to verify that all adapters are connected to 802.3ad compliant switch ports
kernel:magg0: An illegal loopback occurred on adapter (eth1-Mgmt2)
I have verified both the Check Point side of things and the switch side of things. Everything should be good. But these messages keep on appearing. This is my first time running 802.3AD/LACP on magg, everyone else I'm working with is running XOR.
There is only a single Security Group, not being able to share magg shouldn't be a problem. Unless "Dual-Site" and the fact that we have two chassis as a result of this also counts as "shared"?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 to be sure, did you checked twice your DualSite deployment. The magg0 should be build with interfaces from one site, only. Meaning from only one MHO in your described deployment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hmm.. Is this true when you have a Single Orch per site in a dual-site configuration? From the documentation, this isn't very clear. It mentions, "Important - When you connect two Quantum Maestro Orchestrators for redundancy, the Check Point Management Server connects only to one of the Quantum Maestro Orchestrators."
We don't have "redundancy" per se, as we only have a single orchestrator per site/chassis. How would this work? Site 2 is a disaster recovery site if there is a power outage, fire, flood, etc., taking out Site 1. How would Site 2 operate if it has no magg connections located on Site 2?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The wording in the admin guide is also quite confusing. It only states that the management will only send traffic to one orchestrator. This makes sense as the management sends all traffic to the SMO, then the SMO spreads it across the security group members. This doesn't tell me much regarding magg should only be connected to a single orchestrator. This doesn't make any sense to me from a logical standpoint. So if Site 1 goes down, the Orchestrator with it, the SMO moves to Site 2 but is supposed to incapable of receiving management traffic?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the site1 goes down the SMO moves to site 2 and the configuration of the management interface moves too. Sounds something magic but it's how it works. There is no need to add interfaces from the other site in the SGs configuration.

I fully agree your confusion. It was the same to me with our first Dual Site deployment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Pretty sure this equals to what we currently have going:
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer3+4 (1)
Use RxHash: 0
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 200
Down Delay (ms): 200
802.3ad info
LACP rate: slow
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: 00:1c:7f:aa:bb:00
Active Aggregator Info:
Aggregator ID: 4
Number of ports: 2
Actor Key: 15
Partner Key: 19
Partner Mac Address: 00:04:96:9b:bd:09
Slave Interface: eth1-Mgmt1
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 1
Permanent HW addr: 00:1c:7f:a4:2d:d2
Slave queue ID: 0
Aggregator ID: 4
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:1c:7f:aa:bb:00
port key: 15
port priority: 255
port number: 1
port state: 61
details partner lacp pdu:
system priority: 0
system mac address: 00:04:96:9b:bd:09
oper key: 19
port priority: 0
port number: 1019
port state: 61
Slave Interface: eth1-Mgmt2
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 1
Permanent HW addr: 00:1c:7f:a4:2d:d2
Slave queue ID: 0
Aggregator ID: 4
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:1c:7f:aa:bb:00
port key: 15
port priority: 255
port number: 2
port state: 61
details partner lacp pdu:
system priority: 0
system mac address: 00:04:96:9b:bd:09
oper key: 19
port priority: 0
port number: 1019
port state: 61
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This configuration looks good to me and the description of your connections is correct. How about the switch part of the configuration?
Have you done any SG configuration at site 2 before you connect both sites ? There should be no other configuration before connecting both sites then setting dual site, orchestrator amount, site ID and site sync port.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 I agree, the documentation regarding Dual Site deployment isn't clear. In short and simple ... you have to configure all on only one site and the other will be a "copy" of your first.
You configure one mgmt interface on your MHO and the corresponding interface on the other MHO will be used automatically. No configuration is needed if you deploy DUAL SITE. No LACP bond with interfaces from both sites needed. Failover of MGMT will be done if site 1 goes down.
You can configure a magg with two interfaces from site 1 to your switch-environment on site 1. And the same is used on the other site with no need for an extra configuration on site 2. All what is needed ... you have to define the environment as dual site and define where your MHOs are located (site 1 or 2).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
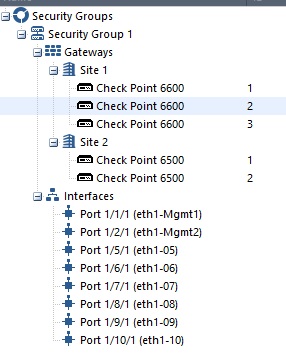
This is basically what we have already. Site 1 and Site 2 are identical in terms of configuration. Port 1-2 is used on both Orchestrators, and the same ports are used for downlink on both sides. The only difference is that Site 1 consists of 3x CPAP-SG6600 appliances, while Site 2 consists of 2x CPAP-SG6500 appliances.
magg0 is configured with LACP and this made the most sense to us as it is supported on R81.20. I can't see a single reason to opt for XOR over LACP when LACP is supported? So judging by your comment nothing is wrong with our setup. Started to worry about missing something crucial here when you started mentioning that Orch2 shouldn't be connected to magg at all.
Which brings us back to the messages from /var/log/messages.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 again. If you run DUAL SITE deployment, only interfaces from one site should be attached your SG configuration.
See my screenshot in last post.
And no BOND should be configured with interfaces from both sites !
To be sure we are talking about the same DUAL SITE...You have these settings on your MHOs?
site 1
set maestro configuration orchestrator-site-amount 2
set maestro configuration orchestrator-site-id 1
set maestro port 1/47/1 type site_sync
site 2
set maestro configuration orchestrator-site-amount 2
set maestro configuration orchestrator-site-id 2
set maestro port 1/47/1 type site_sync
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No configuration for magg on the security group? At all? How would one make magg into LACP then? Which is supposedly supported? Not sure how I can revert this? I don't think manually removing magg0 in the configuration is a smart move?
add bonding group 0 mgmt
set bonding group 0 mode 8023AD
set bonding group 0 lacp-rate slow
set bonding group 0 min-links 0
set bonding group 0 mii-interval 100
set bonding group 0 primary eth1-Mgmt2
set bonding group 0 down-delay 200
set bonding group 0 up-delay 200
set bonding group 0 xmit-hash-policy layer3+4
Compared to another enviroment I have running, without LACP it looks like this:
add bonding group 0 mgmt
set bonding group 0 mode xor
set bonding group 0 xmit-hash-policy layer2
Only real difference is how we have deployed LACP, not XOR? I can't locate anything in the admin guide telling us to not run the bonding commands on the security group?
It specifically tells us to do it, and doesn't mention anything about avoiding it on Dual-Site?
https://sc1.checkpoint.com/documents/R81.20/WebAdminGuides/EN/CP_R81.20_Maestro_AdminGuide/Content/T...
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, that's annoying in the documentation.
In your case with only one MHO on both sites you can configure a magg with two interfaces from one MHO. and these configured magg will be failover automatically to the other site if the site goes down. The only thing to configure on the other site will be the switch LACP configuration . And there is no need for a LACP bond on the switches spanning over both sites. There should be one LACP channel on your switches at site 1 and another one on your switches at site 2.
Without redundancy at the same site you don't need a magg, only one interface should be used at site 1 and no configuration is needed at site 2.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
But isn't this what we are already running? The bonding serves multiple purposes. We want to utilise both eth1-mgmt and eth2-mgmt, port 1 and port 2 on Orchestrator-1 (Site 1). This is because the customer wants both redundancy on port level and switch level. By utilising port 1 and port 2 like this, we create a scenario where port 1 or port 2 can fail, without magg dropping from Orchestrator-1. By running LACP using VPC on the switch side of things, the customer creates a scenario where they can reboot and patch switch-1 without dropping magg as it is also connected to switch-2.
A similar configuration is applied on Site-2, where Orchestrator-2 has the exact same configuration with port-1 connected to one switch and port-2 connected to another switch.
This makes the configuration in Gaia look like this on all five security group members:
add bonding group 0 mgmt
set bonding group 0 mode 8023AD
set bonding group 0 lacp-rate slow
set bonding group 0 min-links 0
set bonding group 0 mii-interval 100
set bonding group 0 primary eth1-Mgmt2
set bonding group 0 down-delay 200
set bonding group 0 up-delay 200
set bonding group 0 xmit-hash-policy layer3+4
This makes the bond look like this:
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer3+4 (1)
Use RxHash: 0
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 200
Down Delay (ms): 200
802.3ad info
LACP rate: slow
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: 00:1c:7f:aa:bb:00
Active Aggregator Info:
Aggregator ID: 4
Number of ports: 2
Actor Key: 15
Partner Key: 19
Partner Mac Address: 00:04:96:9b:bd:09
Slave Interface: eth1-Mgmt1
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 1
Permanent HW addr: 00:1c:7f:a4:2d:d2
Slave queue ID: 0
Aggregator ID: 4
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:1c:7f:aa:bb:00
port key: 15
port priority: 255
port number: 1
port state: 61
details partner lacp pdu:
system priority: 0
system mac address: 00:04:96:9b:bd:09
oper key: 19
port priority: 0
port number: 1019
port state: 61
Slave Interface: eth1-Mgmt2
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 1
Permanent HW addr: 00:1c:7f:a4:2d:d2
Slave queue ID: 0
Aggregator ID: 4
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:1c:7f:aa:bb:00
port key: 15
port priority: 255
port number: 2
port state: 61
details partner lacp pdu:
system priority: 0
system mac address: 00:04:96:9b:bd:09
oper key: 19
port priority: 0
port number: 1019
port state: 61
I don't think any of this is wrong. The configuration is identical for member 1_01-1_03 as it is on 2_01-2_02. What exactly is wrong with our configuration? I think we are talking past each other. I don't think we are required to change anything? The configuration is correct but for some reason, we are seeing these strange messages in /var/log/messages for whatever reason.
Or do you think the configuration is wrong?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have to verify with the customer regarding the switch side of things. From what I understand from all of this is that Site 1 and Site 2 should not have the same logical LACP bond on the switch side of things. As the Orchs themselves are rather "dumb", we can't have the switches firing traffic at random to whichever port they feel like. On the switch end this has to exist as aka group-1 and group-2, where group-1 consist of the two ports from Site 1, and group-2 consist of the two ports on Site 2. This will ensure that managementtraffic will always get to Orch-1 when Chassis 1 is active, and to Orch-2 when Chassis 2 is active.
Does the same logic apply to the uplink? Uplink on Site 1 should run in a seperate LACP group compared to the Uplink on Site 2? To ensure that traffic doesn't bounce between sites unexpectetly as a result of the LACP logic?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 Yes, you‘ve got a correct understanding. The same configuration design is applied to the LACP groups for management and uplink ports.
With dual site deployment you have an active and a standby site, only SGMs on the active site are processing the traffic of the SG. If the site will fail all is failing over to the surviving site and the SGMs on the the formerly standby site are going active and this sites SGMs are processing the traffic.
If you use VSX you can use both sites, but only for distribution of different VS. The traffic of one VS will be processed at site 1 and only at site 1, but you can deploy another VS and run this at the other site 2.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The customer has confirmed that Orch-1 and Orch-2 do not share anything. There is no VPC or anything that puts Orch-1 and Orch-2 in the same bonding group. As far as I can tell there is nothing wrong with the configuration or deployment.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 looks like everything will be fine. Does TAC any troubleshooting or has an idea what‘s wrong?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have a ticket. But sadly, my experience with TAC cases regarding Maestro isn't all that great, and this one doesn't look any different.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had a maintenance window with the customer earlier today. Sadly, the TAC representative got short on time due to miscommunication and timezone differences. But as we had a maintenance window, I convinced the customer to at least try to change the MAGG bond from LACP to XOR to see if it behaves any differently, as we have these LACP-related errors in /var/log/messages. After changing it from LACP to XOR on the Check Point and switch side, there were no issues afterwards.
This deployment hasn't had a working HA Active Up Dual-Site since we changed it from Single to Dual Site in February. After the change to XOR, we could bring up Chassis 2. Do failovers back and forth, patching Orchestrators and whatnot with no issues.
This is surprising as I don't fully understand how non-working LACP on the MAGG interface would affect the interoperability between chassis in such a significant way. There shouldn't have been any issues with the LACP deployment, either. This is Maestro VSX, and the MAGG acts as the management interface for VSX. I'm unsure if that makes the deployment more reliant on the MAGG bond. I would expect trouble with MAGG to cause issues with management traffic—things like pushing policy, logging, vsx_util, etc.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The configuration on the Orchestrator looks like this:
Site 1:
show maestro configuration orchestrator-site-amount
Number of configured Orchestrators Sites in this Maestro deployment is 2.
show maestro configuration orchestrator-site-id
The Site ID of this Orchestrator is 1.
show maestro port 1/47/1 type
Port 1/47/1 type is site_sync
show maestro port 1/48/1 type
Port 1/48/1 type is site_sync
Site 2:
show maestro configuration orchestrator-site-amount
Number of configured Orchestrators Sites in this Maestro deployment is 2.
show maestro configuration orchestrator-site-id
The Site ID of this Orchestrator is 2.
show maestro port 1/47/1 type
Port 1/47/1 type is site_sync
show maestro port 1/48/1 type
Port 1/48/1 type is site_sync
All interfaces assigned to the Security Group are from Orch-1. There doesn't seem to be any option when running R81.20 on the Orchestrator as Dual-Site config to add interfaces from Site 2, as they are unavailable and not shown as an option.
The customer has also confirmed that Orch-1 and Orch-2 do not share anything. There is No VPC or anything that puts Orch-1 and Orch-2 in the same bonding group. As far as I can tell there is nothing wrong with the configuration or deployment.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Couple of things:
In a dual-site deployment, when you assign a port to a security group, it is assigned from both sites. So, port 5 on your orchestrator on both sides is named 1/5/1, and when you assign it to a group that is applied on both sites.
Second, it's not supported to change the port type for the default ssm_sync port. So I recommend changing port 48 back to ssm_sync and assigning a different port as the extra site_sync port. While doing this, make sure that port 1/56/1 is not also a site_sync port, as it will default to this and I've seen it cause weirdness when it's assigned but not in use.
-
You cannot change the type of the dedicated Internal Synchronization port:
-
MHO-175 - Port 32
-
MHO-170 - Port 32
-
MHO-140 - Port 48
-
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the information. It's been so long since we did the deployment, that I can't remember which port we re-assigned to get bonded SYNC. Currently, we are using port 47 and port 48 to get bonded SYNC.
We haven't had any issues with SYNC as far as I know. We had a maintenance window last week and the person from TAC had to leave due to time constraints caused by miscommunications on the time (darn timezones). I ended up using the maintenance window to test out various things, and changing from LACP to XOR on the magg bond has seemed to solve all issues.
I figured as we are seeing these kind of messages in /var/log/messages points to LACP not working:
kernel:magg0: An illegal loopback occurred on adapter (eth1-Mgmt1)
kernel:Check the configuration to verify that all adapters are connected to 802.3ad compliant switch ports
kernel:magg0: An illegal loopback occurred on adapter (eth1-Mgmt2)
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@RamGuy239 It‘s been a while, did you find the root cause of your problem with the flooded messages?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Wolfgang Sadly, we did not. And the customer doesn't want to go deeper into that rabbit hole as things are working using XOR. They'll stick with XOR over LACP and call it a day.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Believe the documentation is being amended to confirm this is now supported in R81.10
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is one limitation to what @Dario_Perez mentioned. If you intend to share the management interface between security groups, LACP is still not supported.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is this because only the SMO Master participates in LACP and if you are sharing the management interface between Security Groups you can't have more than one SMO Master trying to do LACP with the management port?
Gateway Performance Optimization R81.20 Course
now available at maxpowerfirewalls.com
now available at maxpowerfirewalls.com
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 4 | |
| 4 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |
About CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2024 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter