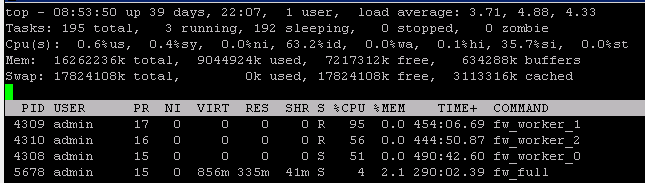
Petr Hantak had some excellent suggestions, to dig in a little deeper you need to determine which specific type of CPU execution is tying up the CPU; this will give you some important clues about where to focus your efforts The best tool for this is running top in real-time while the event is occurring, sar can also be used in historical mode but it rolls up the sy/si/hi/st values shown in top into a single figure (%system) which can obscure where the issue is occurring. top can be run in batch mode to catch intermittent spikes which is covered in my book.
So if you run top look at the us/sy/ni/id/wa/hi/si/st values which are listed below along with hints about how to proceed if that particular value is the high one:
us - Consumption by processes, should be fairly low on a gateway unless there are features enabled such as HTTPS Inspection which cause "process space trips" on the firewall; this effect and what you can do about it is extensively covered in the second edition of my book. fwd or its buddies can definitely be a culprit here if the gateway logging rate is extremely high as well. Note that fw_worker_X CPU execution is NOT counted here, even though they look like processes, see sy below.
sy - CPU consumption processing traffic in the Firewall (F2F) and Medium (PXL) paths, fw_worker_X CPU usage is usually counted here. The fw_worker_X "processes" shown in top are simply representations of the firewall workers down in the kernel and not really processes in the traditional sense, in some cases CPU usage by fw_worker_X "processes" will appear under si, see below.
ni - Execution by processes that have had their process CPU priority lowered (nice'd), irrelevant on a gateway but important on an SMS.
id - Idle time, hopefully self explanatory.
wa - Percentage of time a CPU was blocked (unable to do anything) waiting for an I/O event to occur (usually hard drive access). Anything higher than 5% here (unless policy is currently being installed) is probably a low free memory situation on a gateway, use free -m to investigate further. Any nonzero swap usage may indicate the need for more RAM or the presence of a runaway process consuming excessive amounts of memory.
hi - Percentage of CPU time processing hardware interrupts, on a gateway this is almost all the transfer of packets from the NIC hardware buffers into RAM memory (ring buffer). An excessive value here could indicate extremely high packet rates traversing the firewall or possibly a NIC hardware/driver issue.
si - Soft Interrupts, SoftIRQ processing (i.e. emptying the ring buffer and sending the packets up for inspection) AND the handling of fully-accelerated traffic in the Accelerated path (SXL). If this value is high and your cores allocated to SND/IRQ functions are getting slammed, you may need to reduce the number of Firewall Worker cores so that more SND/IRQ cores can be allocated.
st - Steal - Percentage of CPU cycles requested but denied by the Hypervisor. On a bare-metal firewall (i.e. non VSec/VE) this should always be zero.
--
Second Edition of my "Max Power" Firewall Book
Now Available at http://www.maxpowerfirewalls.com
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization