- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
The State of Ransomware Q1 2026
Key Trends and Their Impact
Good, Better, Best:
Prioritizing Defenses Against Credential Abuse
AI Security Masters E7:
How CPR Broke ChatGPT's Isolation and What It Means for You
Blueprint Architecture for Securing
The AI Factory & AI Data Center
Call For Papers
Your Expertise. Our Stage
CheckMates Go:
CheckMates Fest
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- General Topics
- :
- Re: Could not connect to "cws.checkpoint.com:80"
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
Could not connect to "cws.checkpoint.com:80"
Hello-
Every couple of hours or so we receive the message below from our internet facing gateway(s) though curl shows connectivity every time I check for a connection after getting this alert. I've seen in this in production and a lab environment; I've also heard that others experience the same. I'm curious to know why this occurs at all and am open to suggestions in trying to solve, or at least mitigate, the occurrences.
SK109105 did not seem to help me and we do not use HTTPs inspection or a proxy server. Both our mgmt server (VM) and this HA (open source) cluster is running 80.10 patch level 112.
Thank you
Validation:
[Expert@FWFront001:0]# curl cws.checkpoint.com:80
<html><body><h1>It works!</h1></body></html>
[Expert@FWFront001:0]# cpstat -f RAD_status urlf
RAD status: -
RAD status description: -
Email message:
HeaderDateHour: 12Sep2018 8:21:00; ContentVersion: 5; HighLevelLogKey: N/A; LogUid: N/A; SequenceNum: N/A; Action: ctl; Origin: FWNameHere; IfDir: >; InterfaceName: daemon; Alert: useralert; OriginSicName: N/A; OriginSicName: ; HighLevelLogKey: 18446744073709554515; description: Failed to connect to Check Point Anti Malware detection service.; reason: Could not connect to "cws.checkpoint.com:80". Check proxy configuration on the gateway.; severity: 3; update status: Failed; ProductName: Anti Malware; ProductFamily: Network;
2 different error logs (could not connect and Internal error occured, could not connect)
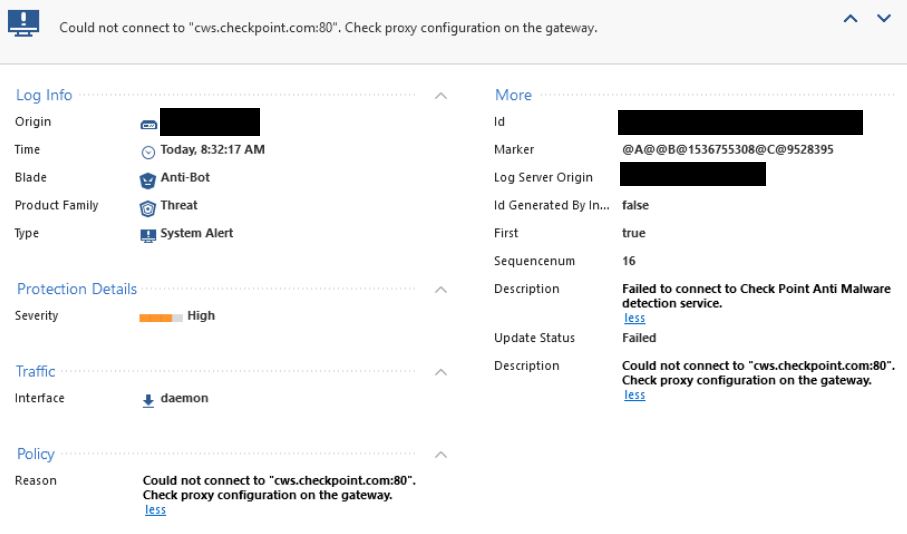
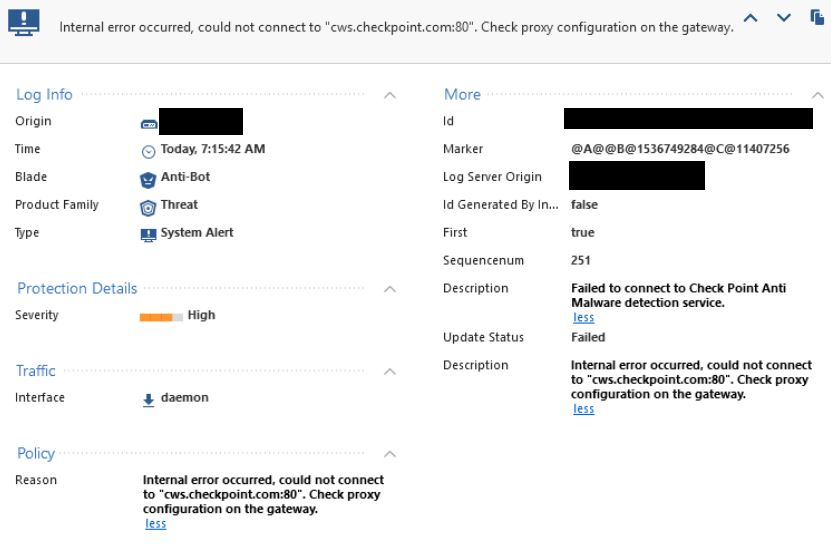
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
is this when you have the smartconsole open it occurs? or even when it is shutdown you still get this issue ?
you want to look at sk98665 and run through this
Thanks
Frank
28 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
is this when you have the smartconsole open it occurs? or even when it is shutdown you still get this issue ?
you want to look at sk98665 and run through this
Thanks
Frank
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would have to guess smartconsole is open as we have ~15 people in it at any given time (assuming you mean the application is open on someone's desktop). I will take a look at SK98665 and report back. Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kevin,
if the console open then what will happen and I can't find info to prove this is that it will try to use the local host, so the desktop that has the client open will try download the updates via there pc. but this will not work if you have a proxy configured on the pc, you will need either add proxy configuration to smartconsole and then the updates wont fail.
look at this.
the other SK I gave you probably wont yield any information I expect and the cause is the client is open on the desktop.
let me know what you find I hope this helps you.
Thanks
Frank
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Last night I finally was able to test the theory of having all smart console sessions disconnected and closed on our endpoints (~15 PCs). Unfortunately I still received a couple emails with the described error so I don't think the consoles being opened is playing a part. Thank you though.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This was occurred one of my firewall as well then I checked all updates and no issue found( all are up to date).
Finally, reboot the firewall then error message has gone
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We also see this problem, but only from our primary internet gateway.
If I change member so that it's HA partner is active, then the alerts are generated from that firewall and the other stops sending the alerts.
We see this at random times of the day, nothing repeatable, nothing to pinpoint it to other ongoing activities that might be swamping our internet connection (which was unlikely anyway).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Paul,
Take a look at this article Anti-Virus / URL Filtering / IPS update fails on the Standby member of ClusterXL in High Availabilit...
mainly this part my friend
If the above steps do not resolve the issue, then the cluster has to be configured not to hide these connections behind the cluster Virtual IP address.
On the Security Management Server, modify the relevant "table.def" file per sk98339 - Location of 'table.def' files on Security Management Server.
The following should be added to the 'no_hide_services_ports' configuration if traffic can not be synchronized:
| Traffic Name | Traffic Port | Configuration in no_hide_services_ports |
| HTTP | TCP port 80 | <80, 6> |
| HTTPS | TCP port 443 | <443, 6> |
| DNS | UDP port 53 | <53, 17> |
Thanks
Frank
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Our problem is not with the standby firewall, but the active one. E.g. firewall1 which is active generated the above alert, firewall 2 does not.
If we changeover so 1 is standby and 2 is active, 1 stops sending this email alert and 2 does. The problem is only seen on the active firewall.
Cheers,
Paul.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Paul,
with firewall 1 which is active you get this error ? you need to go over this sk98665 and provide more info its a long procedure but worth going over.
which version of checkpoint are you running and Jumbo take ? patches ?
this may help you also Security Gateway cannot connect to Check Point Anti-Bot / Anti-Virus Online Web Services
Thanks
Frank
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, I was this problem standby member.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi - sorry for the delay. I wanted to pass along what I found despite all the good tips above. After running across sk83520 and testing connections, I found that the gateways could not access updates.checkpoint.com at 209.87.209.87 - even though I have a non FQDN domain object destination of .checkpoint.com in place. I could reach cws.checkpoint.com as I showed in the original post and I could reach checkpoint.com too (Expert mode# curl_cli -v -k https://updates.checkpoint.com/). I don't know why this is, so instead of messing around I just added the IP. Once pushed I found the alerts stopped. Thanks for everyone's help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Paul Stephenson and I have been looking in to the same issue at his place and your observations are interesting.
When you say you added the IP - I assume you added that to a host object, but then what did you use the host object for? As an exclusion to the access or application policy or HTTPS override or something else?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey folks - Well, firstly, I spoke too soon. I just woke up to 55 emails from overnight claiming the active gateway can't connect. I also failed to mention that I changed the Threat Prevention engine setting (advanced) to "Background" verses "hold". Regardless I am still seeing the email alerts (posted below for simplicity). What I mentioned above about the IP was actually this network group from our 77.30 days. I added this group in a destination rule (along with non FQDN object .checkpoint.com). Once I did this both gateways went from red Xs to green "ok", I believe because they got to 209.87.209.87 which is where I had been seeing drops (which is odd anyway because I had the non FQDN and other IPs did work). I'll try to dig around some more today, this is getting really frustrating though.

HeaderDateHour: 25Oct2018 7:07:15; ContentVersion: 5; HighLevelLogKey: N/A; LogUid: N/A; SequenceNum: N/A; Action: ctl; Origin: FWFront001; IfDir: >; InterfaceName: daemon; Alert: useralert; OriginSicName: N/A; OriginSicName: ; HighLevelLogKey: 18446744073709551615; description: Failed to connect to Check Point Anti Malware detection service.; reason: Internal error occurred, could not connect to "cws.checkpoint.com:80". Check proxy configuration on the gateway.; severity: 3; update status: Failed; ProductName: Anti Malware; ProductFamily: Network;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fingers crossed, after changing CPUSE update check-ins from constant to every 10 days I haven't seen an email yet, though its only been an hour. Today however we were seeing this email every ~15 minutes.
GAIA webUI, at the bottom of the left hand tree, under /software updates policy you can disable this is completely or expand the check period for up to 10 days.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This ^ didn't work, still received ~6 emails overnight.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all, I also receive a high deal of alerts regarding connections to cws.checkpoint.com:80
But, looking up the DNS resolve these days I noticed it changed the response from our DNS (and public DNS). As it resolve to Akamai services (chained to multiple CNAMEs responses), I believe CP deploy some load balance for this service (and maybe like the TE Cloud, the DNS lookup response depends of the geographic location originating the request).
Maybe CP can code some Application Control signature or similar (Dynamic Object? Updatable Object?) to manage the multiple and different DNS response (which may vary from customer to customer), because deployed in this way we don't have any way to enforce and prioritize this traffic, which is essential to Application Control, URL Filtering, Anti-Bot and Anti-Virus blades.
Below I leave the RAD stats for URL Filtering, take a look on the RAD Down column:
| Day | Date | Time | Rad Up Time | Found in LDB | Sent to Site | Round Trip (ms) | Err: No Response | Err: Application Level | Err: DNS Error | Err: Internal Server Error (500) | Err: Service Unavailable (503) | Err: Other Error Code | Err: Other | Hit Count | Miss Count | Error Count | Cache Size (bytes) | Max Cache Size (bytes) | Cache Total Host Records | Max Cache Total Host Records | Avg Family Size | Max Family Size | Expired Requests | Expired Requests With Response | Rad Down | Service Down |
| Fri | 76254 | 0,3939 | 0,0021875 | 1 | 7 | 498 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5628 | 416 | 0 | 252636 | 258452 | 5223 | 5946 | 0 | 98 | 11 | 2 | 2 | 0 |
I monitored the RAD status (cpstat -f RAD_status urlf) and is not down during the issue.
I don't have any proxy between the gateway and our ISP router, so I believe the HTTP headers are left intact during the request.
Any ideas?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We don't use a proxy either and I have in place an ANY destination over http/s for this cluster. The last couple days I was able to simulate the same message in my home lab. Frankly, I don't get why this occurs so often or what to try next.
DeletedUser
Not applicable
2018-11-09
08:55 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In addition to the great tips mentioned here subscribe for updates on Check Point Services Status page. Got a text last night of an issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Bob, I didn't have knowledge of the Services Status page, I subscribed now (and I saw in fact there is an issue with RAD).
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all, last weekend I installed the last R80.10 JHF for the conflicting gateway and the alerts now appears almost twice per hour.
HeaderDateHour: 12Nov2018 9:56:21; ContentVersion: 5; HighLevelLogKey: N/A; Uuid: {0x0,0x0,0x0,0x0}; SequenceNum: 59; Action: ctl; Origin: AR-MTV-MUNFWGW; IfDir: >; InterfaceName: daemon; Alert: mail; OriginSicName: N/A; description: Failed to connect to Check Point Anti Malware detection service.; reason: Could not connect to "cws.checkpoint.com:80". Check proxy configuration on the gateway.; severity: 3; update status: Failed; ProductName: Anti Malware; ProductFamily: Network;
When the alert occurs I see this behaviour if I test the connection to cws.checkpoint.com using curl_cli:
=====================================
Mon Nov 12 09:56:18 ART 2018
* Trying 104.94.216.82...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Connected to cws.checkpoint.com (104.94.216.82) port 80 (#0)
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0> GET / HTTP/1.1
> Host: cws.checkpoint.com
> User-Agent: RAD_CLIENT
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: Apache
< Last-Modified: Sat, 20 Nov 2004 20:16:24 GMT
< Content-Type: text/html
< Date: Mon, 12 Nov 2018 12:56:19 GMT
< Content-Length: 44
< Connection: keep-alive
<
{ [44 bytes data]
100 44 100 44 0 0 101 0 --:--:-- --:--:-- --:--:-- 156
* Connection #0 to host cws.checkpoint.com left intact
<html><body><h1>It works!</h1></body></html>
Mon Nov 12 09:56:19 ART 2018
=====================================
=====================================
Mon Nov 12 09:56:24 ART 2018
* Trying 104.94.216.82...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Connected to cws.checkpoint.com (104.94.216.82) port 80 (#0)
> GET / HTTP/1.1
> Host: cws.checkpoint.com
> User-Agent: RAD_CLIENT
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: Apache
< Last-Modified: Sat, 20 Nov 2004 20:16:24 GMT
< Content-Type: text/html
< Date: Mon, 12 Nov 2018 12:56:24 GMT
< Content-Length: 44
< Connection: keep-alive
<
{ [44 bytes data]
100 44 100 44 0 0 103 0 --:--:-- --:--:-- --:--:-- 157
* Connection #0 to host cws.checkpoint.com left intact
<html><body><h1>It works!</h1></body></html>
Mon Nov 12 09:56:24 ART 2018
=====================================
Also, attached you'll find the rad.elg log file when the issue happens.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The only way around this, that I have found and works for me, is to allow the cluster out to the internet with a destination of ANY over http/s. Once I did that the alerts stopped. A rule I did have with a domain object destination non-fqdn .checkpoint.com doesn't work since the reverse DNS points to other servers, like Akamai and Akamaiedge. You'd think the internals would account for RDNS, but they don't. Try it for an hour or two and see if your alerts stop, they probably will.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will do Kevin, keep you posted. I also tried with a rule with the non-FQDN object (in access control and QoS rulebase) but didn't work.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kevin Vargo just FYI, I changed the rule for the "cws.checkpoint.com" to "Any" in the destination column as you suggest (not sure how'll respond if we put the "Internet" object on it) and the alert didn't go off since then, so maybe that can be a valid workaround for the issue.
So thanks for keeping my inbox lighter 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good - You'll probably see traffic going to 84.39.153.31 that was once blocked and now likely is going through ok.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yeah, I've this traffic but I've it always allowed as implied, so maybe you've to check if you don't have a misconfiguration on your gateway, because that IP is Check Point's (the reverse resolves the domain ctmail.com, which Check Point documented is used for Suspicious Mail Outbreaks feature and the Anti-Spam blade).
Also, I put the Internet object in the destination instead of Any, and still don't have any new alert regarding the cws.checkpoint.com's connection. But on the other hand, I have some random errors of communication of the Threat Emulation blade (I use the Cloud, don't have a TE Appliance).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Santiago,
I was just looking at your rad log, and it seems to match this article exactly with the errors you see in the rad log.
"Failed to connect to Check Point Anti Malware detection service" message in SmartView Tracker
the parts that dont match are contect length too high in your log in the example I am seeing
'Content-Length: ' is not found
your shows
CRadHttpResponseFindContentLength::fetchValidateContentLengthValue: [ERROR] content length too high > 1000000
you are running R80.10 ? or what version ?
[rad_http_response_find_content_length.cpp:57] CRadHttpResponseFindContentLength::checkContentLength: [INFO] enter to ...
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_http_response_find_content_length.cpp:87] CRadHttpResponseFindContentLength::checkContentLength: [INFO] exit from ..
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_http_response_find_content_length.cpp:240] CRadHttpResponseFindContentLength::fetchValidateContentLengthValue: [ERROR] content length too high > 1000000
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_http_response_find_content_length.cpp:242] CRadHttpResponseFindContentLength::fetchValidateContentLengthValue: [INFO] exit from ..
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_http_response_runner.cpp:94] CRadHttpResponseRunner::run: [ERROR] error running chain <CRadHttpResponseFindContentLength>
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_http_response.cpp:71] CRadHttpResponse::handle_data: [ERROR] CRadHttpResponse:0x13b5ad44 error processing response buffer
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_connection.cpp:473] CRadConnection::CRadPender::handle_data: [ERROR] error processing http response
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_connection.cpp:880] CRadConnection::handle_data: [ERROR] error reading: 0x192f3a48, _dlen = 256
[rad 5771 4134303504]@AR-MTV-MUNFWGW[12 Nov 9:56:21] [rad_fwconn.cpp:1141] CRadFwConn::handle_data: [ERROR] error on data handle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Franco, I already check out that SK. Also I've the last JHF for R80.10:
This is Check Point CPinfo Build 914000190 for GAIA
[IDA]
HOTFIX_R80_10[CPFC]
HOTFIX_R80_10
HOTFIX_R80_10_JUMBO_HF Take: 154
BUNDLE_CPINFO[FW1]
HOTFIX_R80_10
HOTFIX_R80_10_JUMBO_HF Take: 154
BUNDLE_CPINFOFW1 build number:
This is Check Point's software version R80.10 - Build 124
kernel: R80.10 - Build 104[SecurePlatform]
HOTFIX_R80_10_JUMBO_HF Take: 154
BUNDLE_CPINFO[PPACK]
HOTFIX_R80_10
HOTFIX_R80_10_JUMBO_HF Take: 154
BUNDLE_CPINFO[DIAG]
HOTFIX_R80_10[CVPN]
HOTFIX_R80_10
HOTFIX_MABDA_R80_10_J103_884[CPUpdates]
BUNDLE_R80_10_JUMBO_HF Take: 154
BUNDLE_CPINFO Take: 0[CPinfo]
No hotfixes..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have the same, 80.10 JHF 154. I am getting similar email messages now on our internet facing clusters I see this morning.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 8 | |
| 5 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 2 |
Upcoming Events
Tue 12 May 2026 @ 10:00 AM (CEST)
The Cloud Architects Series: Check Point Cloud Firewall delivered as a serviceWed 13 May 2026 @ 11:00 AM (EDT)
TechTalk: The State of Ransomware Q1 2026: Key Trends and Their ImpactThu 14 May 2026 @ 07:00 PM (EEST)
Under the Hood: Presentando Check Point Cloud Firewall como ServicioTue 12 May 2026 @ 10:00 AM (CEST)
The Cloud Architects Series: Check Point Cloud Firewall delivered as a serviceAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter