- Products
Quantum
Secure the Network IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloudGuard CloudMates
Secure the Cloud CNAPP Cloud Network Security CloudGuard - WAF CloudMates General Talking Cloud Podcast Weekly Reports - Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
CheckMates Fest 2025!
Join the Biggest Event of the Year!
Simplifying Zero Trust Security
with Infinity Identity!
Operational Health Monitoring
Help us with the Short-Term Roadmap
CheckMates Go:
Recently on CheckMates
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Quantum
- :
- Threat Prevention
- :
- Re: Halting RAD requests handling / RAD reached ma...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Halting RAD requests handling / RAD reached maximum allowed concurrent request
Hello everybody,
we have had a support case running for a long time, but wanted to ask if anyone else still has the problem? The bug has been chasing us since R80 / currently with R80.40. br alois
22 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure if it is the same, but sk103422 was a solution for an issue I had with RAD.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
good day, many thanks for your answer - unfortunately that only works with r70 - the cache_size for url_filter / max_conn in guidbedit rad_services only works in r70 according to support and our experience. br alois
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please provide the exact error message you are seeing, as there have been a variety of issues with rad. Most of the capacity issues seemed to get solved by this: sk163793: How to scale up requests/responses RAD handling rates
Make sure the DNS servers you have defined in Gaia on the gateway are speedy and working correctly by testing them with the nslookup command. Having to wait for slow DNS service can cause issues with rad.
Also try running rad_admin stats on urlf then visiting the RAD screen of cpview which can be quite informative about how rad is working and give you hints about what issues it is having. Don't forget to run rad_admin stats off urlf when done! If rad is having issues, from a user perspective the most common impact to performance tends to be URLF due to its need to hold user connections and query the ThreatCloud, so I'd start there.
Finally, check for this corner case with URL filtering: sk90422: How to modify URL Filtering cache size?
Attend my 60-minute "Be your Own TAC: Part Deux" Presentation
Exclusively at CPX 2025 Las Vegas Tuesday Feb 25th @ 1:00pm
Exclusively at CPX 2025 Las Vegas Tuesday Feb 25th @ 1:00pm
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi, URLF - is not activated at all, the problem is related to AntiBot and DNS Trap. Also an interesting info - the URLF sk works only with R70x, also the RAD connection in the regedit makes no improvement, think the problem is that we have a lot of dns requests and the rad handler is pushing the limit here - and also for one week the cp support does not find the setting. br alois
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any suggestions for a speedy DNS server? We are seeing similar problems with the RAD error message (description: Halting RAD requests handling; reason: RAD reached maximum allowed concurrent requests). The odd thing is I had over 22000 messages in my Inbox since 12:45 in the morning with an additional 2000 after deleting that batch in just one hour.
In either case, we have been trying to use 1.1.1.1 as a DNS server and in the past we used Google's 8.8.8.8. Not certain what their "caching" ability is. Our other option is to use our internal DNS servers, which ultimately (since these lookups for external hosts) will go through 1.1.1.1 and 8.8.8.8. I know our internal servers will cache those lookups for the TTL, but if the Google and 1.1.1.1 also cache information it just seems like extra traffic I'm sending in to the local DNS, to only have to go out the same firewall to do the external lookup.
Is there anything specifically that this needs to lookup in DNS? I was under the impression that RAD used a central Checkpoint service but perhaps I'm wrong. I'll need to do a deeper dive into RAD.
We're running a scalable platform Maestro, and I think I'll be opening a TAC case to get the hotfix mentioned in the SK you referenced.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your firewall should be configured to query your internal DNS servers, who then should ideally be directly querying the root Internet DNS servers, and not going through a DNS forwarder at your ISP or something like 8.8.8.8. Bottom line is to make sure the firewall itself is pointed at valid DNS servers that are not overloaded.
Attend my 60-minute "Be your Own TAC: Part Deux" Presentation
Exclusively at CPX 2025 Las Vegas Tuesday Feb 25th @ 1:00pm
Exclusively at CPX 2025 Las Vegas Tuesday Feb 25th @ 1:00pm
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks. Seems somewhat counter-intuitive given the fact that I send the DNS request in through the internal leg of the firewall, which then goes to the DNS server which then does a lookup (even to the root hints) which passes through the same firewall out to the Internet.
In either case, I think the problem is related to something else at the moment and I'm getting TAC to look at it. My nslookups from our clustered Maestro units are failing. When I perform a ping to the internal network on our bond I get no response back. When I perform a ping to the external bond, I get no response back. Only get a response on a third bond. Oddly enough though is that traffic is routing through the firewall as I'm connected remotely via a VPN, and going through the firewall to access servers, etc. Very strange. However, I've had nothing but problems since we switched to using Maestro so this is no surprise that we're having issues again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Any news regarding this issue?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi guys,
same issue here. A lot of "RAD reached maximum allowed concurrent requests" messages. We can confirm that the responsible is the "Anti-Virus/Anti-Bot" protection. Indeed, when those blades are disabled, no error message appears. We also tried to follow @Timothy_Hall suggestions by adding our internal DNS servers within "Internal DNS Servers" section of Malware DNS Trap item, as well as in Gaia OS, but we didn't have success.
Please see attached screenshots.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Tim.
This error resolved for me, after changing DNS server
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is the response I got back when I had opened a case about seeing that message in our environment, and this has worked for me. To be honest, I did not see a huge change in memory as mentioned, but every case may be different. Again, for my environment I moved up to 1200 initially which helped but then needed to increase that to 1500 about two months later. I haven't changed it since and I haven't seen that message for over three months since the last change.
Depending of how many users, we will need to extend the maximum number of flows RAD can open. This will need to be an iterative process, as increasing the number of flows RAD is allowed to handle will cause RAD to use an equal amount more RAM.
To make the increase, modify the value of the following line in $FWDIR/conf/rad_conf.C:
:max_flows (1000)
Begin by increasing this value by 100 or 200, install policy and restart RAD as done previously with "rad_admin stop ; rad_admin start". Pay close attention to the gateway's memory usage, as RAD's maximum memory usage will increase to scale with how many flows it can handle at once.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello @Trevor_Bruss , thanks for sharing your solution.
I've checked my $FWDIR/conf/rad_conf.C and this is its contents:
(
:urlfs_service_check_seconds (7200)
:amws_service_check_seconds (1800)
:cpu_cores_as_number_of_threads (false)
:number_of_threads (0)
:threads_to_cores_ratio (0.334)
:number_of_threads_fast_response (0)
:number_of_threads_slow_response (0)
:queue_max_capacity (2000)
:debug_traffic (false)
:use_dns_cache (true)
:dns_cache_timeout_sec (2)
:use_ssl_cache (true)
:cert_file_name ("ca-bundle.crt")
:cert_type ("CRT")
:ssl_version ("TLSv1_0")
:ciphers ("TLSv1")
:autodebug (true)
:log_timeouts (false)
:log_errors (true)
:number_of_reports (512)
:max_repository_multiplier (20)
:flow_timeout (6)
:excessive_flow_timeout (300)
:transfer_timeout_sec (15)
:max_flows (1000)
:max_pc_in_reply (0)
:retry_mechanism_on (false)
:max_retries (25)
:retry_peroid_mins (15)
)
So, I'll try to follow your solution by increasing :max_flows (1000). Anyway, is it normal such a file is only contained in VS 0? We have a VSX configuration and I discovered that file is not contained in VS 4 (i.e., the virtual system having issues with RAD).
[Expert@lntfw-pgtw2:0]# ls /opt/CPsuite-R80.40/fw1/conf/rad_conf.C
/opt/CPsuite-R80.40/fw1/conf/rad_conf.C
[Expert@lntfw-pgtw2:0]# vsenv 4
Context is set to Virtual Device lntfw-pVSX1_Frontiera (ID 4).
[Expert@lntfw-pgtw2:4]# ls /opt/CPsuite-R80.40/fw1/CTX/CTX00004/conf/rad_*
/opt/CPsuite-R80.40/fw1/CTX/CTX00004/conf/rad_cloud_settings.C
[Expert@lntfw-pgtw2:4]#
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the VSX environment RAD is working under the VS0 only...all the request are sent from VS0.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unfortunately that did not solve my issue. I asked official support. Following the solution in my case:
Open GuiDBedit > Other > rad_services > malware_rad_service_0 -> change the table cache size to (100-200-300k as needed) . They suggest starting with 150k as all environments are individual and you will have to pick the value not too high and not too low.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had a similar case today with these RAD errors. the item you are looking to increase is cache_max_hash_size and they had me change it to 400,000.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Exactly, but at present that solution doesn't completely solve the RAD error logs (even if it solves abnormal CPU spikes). Indeed, they found a lot of these errors in $FWDIR/log/rad_events/errors:
[rad_malware_response_builder.cpp:327] CRadMalwareResponseBuilder::buildKernelFamilyMember: [ERROR] 0xe6246200 unknown pattern type (1000000000) of pattern id #2 = ^firebasestorage\.googleapis\.com/v0/b/docusign-aac5e\.appspot\.com/o/index\.html\?alt=media&token=819455e8-f584-425e-84a6-a81dc95c
[rad_malware_response_builder.cpp:365] CRadMalwareResponseBuilder::buildEntry: [ERROR] 0xe6246200 buildKernelFamilyHost failed
TAC told me RnD is coding a fix.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
can you share your TAC case number so I could pass it on to my SE. After setting the hash size to 400,000, we see it build to 400,000, then it drops to 320,000 and builds again up to 400,000 entries over and over. So, I think we are probably seeing what you are seeing. Odd thing is that we have 2 identical clusters (different datacenters) and this only seems to be happening on one cluster
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SR#6-0002499539
Yes, I can confirm we have same issue. After reaching 400k, it drops again to 320k. What type of configuration do you have? Here 3 x 23900 appliances in VSX with 4 VS.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
our clusters are 2x 23800's running R80.20, T188
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, our cluster is running on R80.40 T87
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hello, I have the same issue. The rad_resp_slow_0 thread consume high cpu. And I see the same logs "RAD reached maximum allowed concurrent requests"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
here is my screen captures.


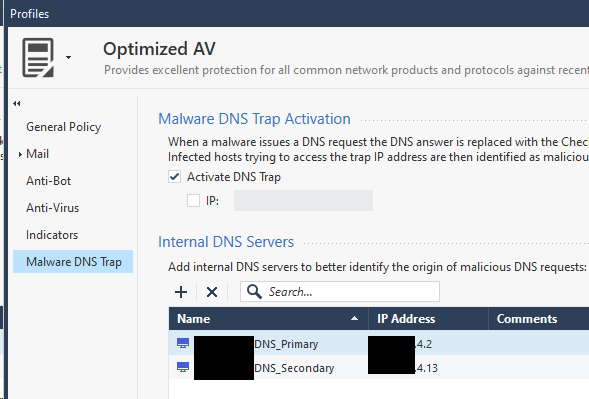{kind=link}
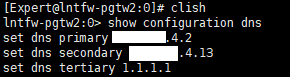{kind=link}
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 3 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |
Upcoming Events
Thu 13 Feb 2025 @ 03:00 AM (CET)
Navigating the Cyber Frontier: A Check Point Executive Briefing - APACThu 13 Feb 2025 @ 03:00 PM (CET)
Navigating the Cyber Frontier: A Check Point Executive Briefing - EMEAThu 13 Feb 2025 @ 02:00 PM (EST)
Navigating the Cyber Frontier: A Check Point Executive Briefing - AmericasFri 14 Feb 2025 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 33: CPX 2025 terugblik!Tue 18 Feb 2025 @ 03:00 PM (CET)
Why Adding SASE to Your Network Infrastructure is a Win-Win - EMEATue 18 Feb 2025 @ 02:00 PM (EST)
Why Adding SASE to Your Network Infrastructure is a Win-Win - AMERICASThu 13 Feb 2025 @ 03:00 AM (CET)
Navigating the Cyber Frontier: A Check Point Executive Briefing - APACThu 13 Feb 2025 @ 03:00 PM (CET)
Navigating the Cyber Frontier: A Check Point Executive Briefing - EMEAThu 13 Feb 2025 @ 02:00 PM (EST)
Navigating the Cyber Frontier: A Check Point Executive Briefing - AmericasFri 14 Feb 2025 @ 10:00 AM (CET)
CheckMates Live Netherlands - Sessie 33: CPX 2025 terugblik!Tue 18 Feb 2025 @ 03:00 PM (CET)
Why Adding SASE to Your Network Infrastructure is a Win-Win - EMEATue 18 Feb 2025 @ 02:00 PM (EST)
Why Adding SASE to Your Network Infrastructure is a Win-Win - AMERICASAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2025 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter