- Products
Network & SASE IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SASE SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloud Cloud Network Security CloudMates General CloudGuard - WAF Talking Cloud Podcast Weekly ReportsSecurity Operations Events External Risk Management Incident Response Infinity AI Infinity Portal NDR Playblocks SOC XDR/XPR Threat Exposure Management
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- AI Security
- Developers & More
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Products Announcements
- Threat Prevention Blog
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
AI Security Masters
E1: How AI is Reshaping Our World
MVP 2026: Submissions
Are Now Open!
What's New in R82.10?
Watch NowOverlap in Security Validation
Help us to understand your needs better
CheckMates Go:
Maestro Madness
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Network & SASE
- :
- Security Gateways
- :
- cluster member down after upgrade from R80.40 to ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
cluster member down after upgrade from R80.40 to R81.20 via CPUSE
Hello
Today we've tried to upgrade a 5600 cluster of two members from R80.40 to R81.20 running OSPF . It finished as a total disaster ,
Standby member was dead after reboot , with these messages
Nov 11 16:58:24 2023 ctsmdpc01fw routed[27361]: [routed] ERROR: cpcl_cxl_runtime_status(1216): HA mode not started
Nov 11 16:58:25 2023 ctsmdpc01fw routed[27361]: [routed] ERROR: cpcl_cxl_runtime_status(1216): HA mode not started
Nov 11 16:58:25 2023 ctsmdpc01fw routed[27361]: [routed] ERROR: cpcl_cxl_runtime_status(1216): HA mode not started
It seems like cluster membership was deleted , Standalone ....lost sync IP , etc...
gateway01fw> show routed cluster-state
Cluster: Standalone
Master/Slave: Master
Sync IP: N/A
Cluster Sync: N/A
We are going to open a SR to Checkpoint but I would like to know if someone has found a similar problem..
thanks
23 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you check if ClusterXL is enabled in cpconfig?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, it was enabled. We tried to disable/ reboot and enable again but the result was the same.
finally we did a revert snapshot
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just in case, did you change the cluster object version and compiled/installed a new policy? was it installed successfully? R80.40 policy version will not work on R81.20. It seems that it loads the default policy, where clustering is not present, hence the HA error
Please post the output from "fw stat"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After upgrade , gateway lost connection with management we had no option to do nothing. We did a revert snapshot
But your observation is absolutely right about modifying object version in management. I think that the object version was not modified initially .
We'll try again in a few days.
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That should not happen. SIC did not work at all?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@_Val_ makes a very good point actually...did you change cluster object to R81.20 in general properties tab?
Best regards,
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Which method / process did you use for the upgrade e.g. MVC and was a policy install performed successfully after?
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello
No, I didn't have the oportunity to enable mvc , install ...nothing.
steps followed
1- Verify the applicable CPUSE Software Packages
2- Download the applicable CPUSESoftware Packages.
3-Install the applicable CPUSE Software Packages.
after step 3 gateway reboot and crashed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thats very unfortunate. I always follow zero downtime upgrade method and never had an issue. Hope TAC can check this further for you.
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I went through a similar event.
Did you have any CT scan results after the event happened to you?
What was the root cause of the problem?
Can you update this post with your comments, please.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Matlu
Yes, as Val indicated it seems to be related to version object change in mgmt server. Our team followed an old procedure used in R80.X upgrades where the standby node was upgraded previously to modify cluster object version in mgmt server. To upgrade to R81.X first of all , object must be upgraded int mgmt . Mistakes when nobody reads the upgrade guide 😞
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Did you use the CPUSE package or the Blink Image package?
When you downloaded the package (either CPUSE or Blink Image), before "Installing" it, you must change the Cluster object version, from the SmartConsole?
This is a previous step before sending to install the package in the passive member?
I have 1 doubt, if you change the version of the Cluster object, before installing the package in the passive member, you have to install "policies"? Or is it just change?
Wouldn't this give more errors?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Matlu
Answering your qüestions
Did you use the CPUSE package or the Blink Image package? CPUSE package
** ************************************************************************* **
** Majors **
** ************************************************************************* **
Display name Status
R81.20 Gaia Fresh Install and upgrade Downloaded <--
When you downloaded the package (either CPUSE or Blink Image), before "Installing" it, you must change the Cluster object version, from the SmartConsole? YES
This is a previous step before sending to install the package in the passive member? YES
I have 1 doubt, if you change the version of the Cluster object, before installing the package in the passive member, you have to install "policies"? Or is it just change? Just change it . After standby node is upgraded then you have to install policy
Wouldn't this give more errors? Yes , install policy will finish ok in R81.20 node and failed in not upgraded node. But you have to deselect option "For gateways clusers, if installation on cluster member fails,do not install on that cluster"
When all members in cluster are upgraded , select this option again
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is part of the reason why I never do or recommend this method. I know it probably goes without saying that changing cluster version has to be done when upgrading, but I find doing zero downtime upgrade seems more "natural" to me, if you will.
I had done it that way for years and never had an issue and besides, literally every customer I ever done this for, they dont care if they lose handful of pings or connecton is down for a minute, hence why this is all done after hours anyway.
Just my 2 cents...
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, Friend
When you upgrade from an old version, for example from R80.30 to R81.20
Do you have to make previous jumps to avoid breaking the Cluster?
Or you can jump directly?
When you change the Cluster object from your SmartConsole, is it just change to the new version, in this case R81.20, and ‘publish’ or is it not necessary to ‘publish’?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
My Name us Naama Specktor and I am checkpoint employee,
I will appreciate it if you will share SR #, here on in PM.
thanks in advanced,
Naama
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just to confirm, I also get this on standby cluster members when installing hotfix's.
I've gone through an R80.40 ClusterXL gateway upgrade tonight. /var/log/messages gets spammed with "[routed] ERROR: cpcl_cxl_runtime_status(1216): HA mode not started" messages every second. I've went from base to T41 and T53 just to check. It does it regardless of the version.
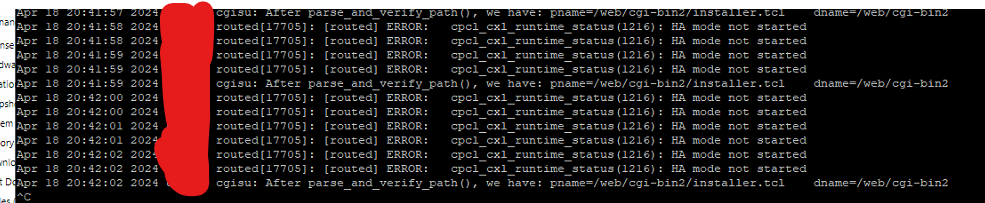{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And if you try cphastop; cphastart ... any change? Reboot?
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there still a solution, i have the same Problem.
Can someone post the SR?
Thanks in advance
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What does cphaprob -a if show?
Andy
Best,
Andy
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andy,
thank you for response.
cphaprob state shows "HA module not started." I didn't run the cphaprob -a if, but i think i get the same output there.
I upgraded the standby FW to R81.20 with the proposed cpuse image, but after the upgrade i got a broken cluster with the alarm "Identity Awareness is not responding". Then i installed the latest HF, also proposed by cpuse and the alarm was still there.
In the Alarm description there was mentioned that the alarm can be caused by different Image Version and should disappear after the upgrade of the primary FW. But after the upgrade the Cluster was offline and broken. In the /var/log/messages is saw "[routed] ERROR: cpcl_cxl_runtime_status(1216): HA mode not started".
I was forced to run a "set snapshot revert AutoSnap..." to activate the automatic created snapshot before the upgrade, because it's a productive system. So currently the FW run with the R81 Release again. I think i will reproduce the problem in a lab environment to have more time for troubleshooting.
Do you have any idea?
Kind Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey
Is this kind of events, is it normal to happen also when doing a JHF upgrade?
We did a JHF upgrade to our VSX Cluster, starting with the STANDBY box.
Suddenly the broken Cluster appeared, and this famous ‘HA not ......’ message.
Is this normal, or is it a bad procedure or a bug in the solution?
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 22 | |
| 17 | |
| 11 | |
| 8 | |
| 7 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |
Upcoming Events
Thu 18 Dec 2025 @ 10:00 AM (CET)
Cloud Architect Series - Building a Hybrid Mesh Security Strategy across cloudsThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldThu 18 Dec 2025 @ 10:00 AM (CET)
Cloud Architect Series - Building a Hybrid Mesh Security Strategy across cloudsThu 08 Jan 2026 @ 05:00 PM (CET)
AI Security Masters Session 1: How AI is Reshaping Our WorldAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2025 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter