- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
AI Security Masters E7:
How CPR Broke ChatGPT's Isolation and What It Means for You
Blueprint Architecture for Securing
The AI Factory & AI Data Center
Call For Papers
Your Expertise. Our Stage
Good, Better, Best:
Prioritizing Defenses Against Credential Abuse
Ink Dragon: A Major Nation-State Campaign
Watch HereCheckMates Go:
CheckMates Fest
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Hybrid Mesh
- :
- Firewall and Security Management
- :
- Re: I have a question about the LACP (8023AD) Bond...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
I have a question about the LACP (8023AD) Bond interface.
There was a service delay at the customer recently.
I think it's because of the structural problem of the bonding interface.
The customer firewall structure is as follows.
* Version: R80.20 Take161
* HA: VRRP
* Bonding mode: 8023AD
* xmit-hash-policy: Layer2
* Interface: 1Gbps Fiber
Finally, it is a structure divided into internal and external parts composed of bonding the upper two interfaces and bonding the lower two interfaces.
The service delay occurred when about 1.5 Gbps of traffic came in.
At this time, ping loss also occurred when ping check was performed with the interface outside the firewall.
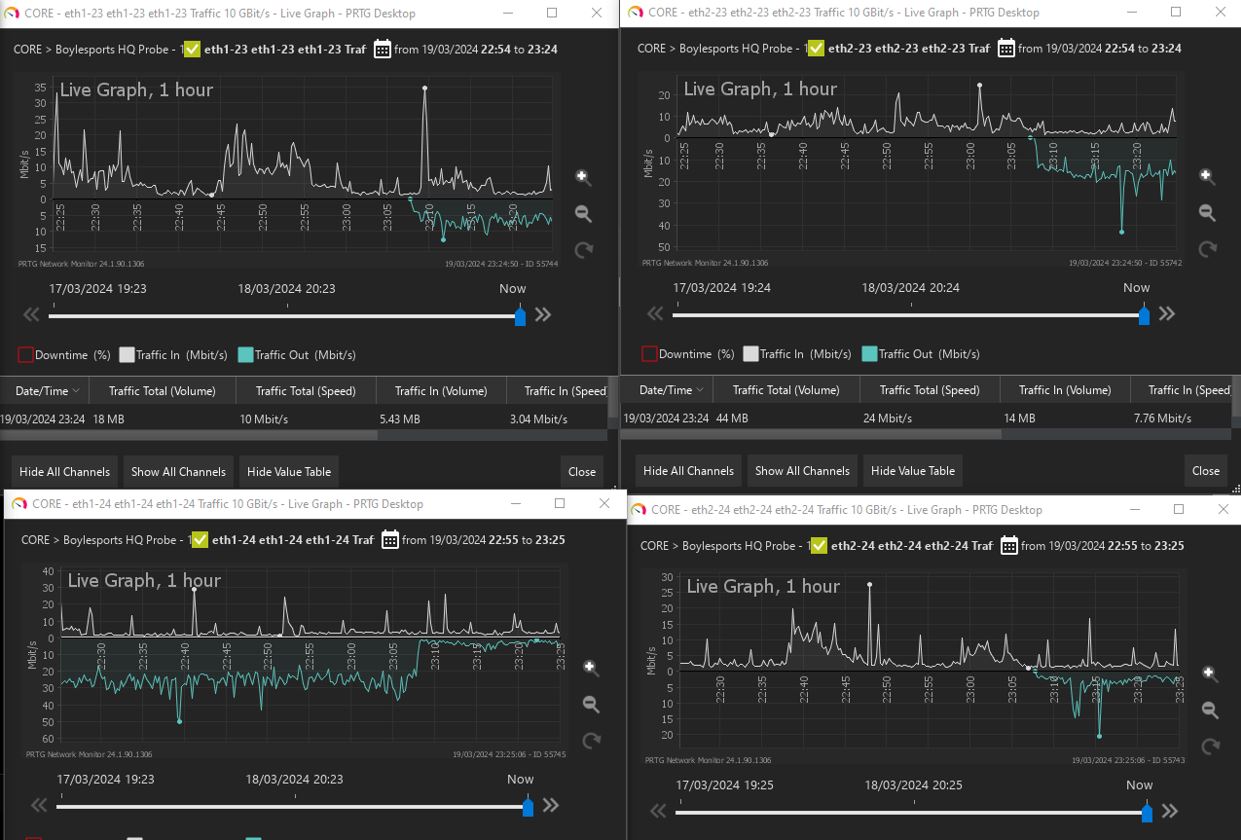
While looking for something unusual, most of the TX traffic was being processed on only one interface.
However, when checking when service delay occurred in cpview history, it was confirmed that traffic was processed in the other interface when the throughput was exceeded in one interface.
I didn't think this would be the root problem, but I changed it to xmit-hash-policy: Layer3+4 for traffic distribution.
(refer to sk111823)
And when monitoring again, traffic distribution was good, and even when traffic close to 2Gbps came in, there was no service delay or ping loss.
From the above symptoms alone, the service delay seems to be caused by improper traffic distribution when more than 1 Gbps of traffic enters the firewall.
When the bandwidth of one interface becomes full in the layer2 method, does the other interface handle the additional traffic?
Or is it MAC-based, forwarding traffic to one interface even when the bandwidth is full?
And what were the other factors that caused service delays?
Note that no network configuration changes have been made.
Thanks for reading this long article.
2 Solutions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I always preferred to align them to L3+L4 for consistency but YMMV.
Which side you change in the first instance depends on if it's the TX or RX where you see the imbalance.
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is no requirement to align hashing algorithms for LACP bonding groups. This is strictly local logic for how the Check Point firewall is going to handle inbound and outbound traffic on the bonding group. Layer 3+4 is preferred as it is more efficient if you are looking for aggregated throughput. It won't make any difference for your switch, it will handle whatever traffic it receives on whatever port in the bonding group. But in order to achieve the best aggregated throughput it's going to be preferable to have the switch do Layer 3+4 as well, making sure you have more efficient handling of aggregated traffic on both ends.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
22 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For 802.3ad bonds on a firewall, the Layer3+4 distribution setting should ALWAYS be used. This is because practically all traffic utilizing a firewall's bonded interface is transiting the firewall, and not destined for the firewall's interface IP itself. If the Layer 2 setting is used, all traffic will congregate on only one physical link as the destination MAC address for all traffic is always the same (that of the firewall), and in most architectures the source MAC address will always be the same as well (that of a core router or other Layer 3 routing device adjacent to the firewall). As a result the same physical interface will always be chosen for all traffic by the transmit hash function, no matter how high the traffic load goes. When the load exceeds the physical link speed of the interface drops will start to occur, it will not try to put more traffic on a less-congested interface.
Also keep in mind that the hash on the firewall is for the TRANSMIT side of traffic only. If there is a serious imbalance on the reception side of the physical interfaces for a firewall bond, you need to check the transmit hash setting on the other device and make sure it is set to Layer3+4 as well. While I do not believe it is strictly required to set the identical transmit hash policy setting on both sides, it is strongly recommended to help keep the physical interface utilization as balanced as possible. While the balancing will never be perfect, my own rule of thumb is that if there is more than a 25% imbalance between the bonded physical interfaces shown by the netstat -ni "OK" counters, some investigation is warranted.
This was all covered on pages 70-72 of my book.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Timothy Hall
I've checked your answer.
Let me summarize what you were trying to convey to me.
1. Even if the traffic exceeds the bandwidth, the traffic flows to one interface because of the transmit hash.
2. The logic distributed and the bandwidth are irrelevant.
But there is something I don't understand.
When checking with CPVIEW History, it was confirmed that another interface was handling traffic when the bandwidth of the interface was exceeded.
also, If you check with the netstat -i command, no errors or drops occur.
I don't know how to interpret this part.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1. Even if the traffic exceeds the bandwidth, the traffic flows to one interface because of the transmit hash.
Correct, it is not adaptive based on utilization. Basically compute the hash based on the setting and dump it out the selected physical interface.
2. The logic distributed and the bandwidth are irrelevant.
Yes, see above.
When checking with CPVIEW History, it was confirmed that another interface was handling traffic when the bandwidth of the interface was exceeded.
Yes, even if one physical interface is saturated some traffic will still happen to be selected for the other physical interface(s) by the hash function.
also, If you check with the netstat -i command, no errors or drops occur.
Did you check the network error/drop counters on the peer device at the other end of the bond? Most of the time drops/misses occur on the receive side, not the transmit side. So the firewall may have been dutifully transmitting traffic out the interface at nearly 1Gbps, but the receiver may well not have been able to keep up. The resulting frame loss probably caused the TCP streams utilizing the saturated link to back off thus decreasing performance. Most 1Gbps interfaces start to run out of gas on the receive side at about 950Mbps and start dropping/missing frames, especially if there are a lot of small or minimum-size frames.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thank you for the reply.
It helped a lot.
Lastly, can you give me the sk or documentation you mentioned about what you're referring to?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quick question, Does this solution also work with VSX. I have multiple VSX Clusters that use bond interfaces. We currently use the Layer2 hash. The bond interfaces are TRUNKS and within the trunks are transports for each VS that is created, so the initial Port-Channel/Bond Interface created does not have Layer3 attributes. Is the firewall smart enough to utilize the Layer3+4 hashing within the TRUNK.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The L3/4 Transmit Hash Policy should function correctly on a trunked interface, the only difference is that the frame L2 headers have a 802.1q portion added into them. Can't see how that still wouldn't work fine.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, @Timothy_Hall
I will just chime in here with a few questions as I'm not that knowledgeable when it comes to LACP algorithms in general. If what you are saying about "For 802.3ad bonds on a firewall, the Layer3+4 distribution setting should ALWAYS be used." is correct why is Layer2 the default setting when enabling LACP?
I've also noticed this:
PMTR-60804 - Bond interface in XOR mode or 802.3AD (LACP) mode may experience suboptimal performance, if on the Bond interface the Transmit Hash Policy is configured to "Layer 3+4" and Multi-Queue is enabled.
To resolve: Configure the Transmit Hash Policy to the default "Layer 2".
And we have articles like sk169977 where issues recently got fixed.
As a result of all of this, I've begun to simply opt for Layer2 to avoid issues. But from what you are saying Layer3+4 should be the default and preferred option?
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not sure why Layer 2 distribution is the default (lower overhead perhaps?) but you can get away with it as long as one of your physical interfaces does not approach the saturation point. However as observed earlier in this thread once that happens traffic performance will be adversely affected, and LACP will not change its behavior when this occurs and will happily keep trying to dump traffic out of the saturated interface.
Yes I recall there was some kind of problematic interaction between Multi-Queue and LACP (PMTR-60804), but that has been fixed in all recent Jumbo HFAs.
As I said earlier Layer 2 mode is fine until one of your physical interfaces gets saturated due to an imbalance, but if that is happening frequently and a physical interface dies or gets unplugged, the remaining interface would be heavily oversubscribed and you'd definitely notice that level of degradation. So maybe you are actually better off using Layer 2 so you'll start to see performance issues before they become critical due to a physical interface failure, and you'll know you need to add more physical interfaces to the bond.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This post is older but I thought I would try to reuse this existing post since it is very similar to my situation.
We have a bond consisting of 5 1Gbps copper interfaces that connects to a Cisco Catalyst switch. This is a HA 15600 Cluster in Active/Standby mode so this only references the active gateway, bond, and physical interfaces. We are seeing a very high imbalance where basically only 1 of the 5 interfaces seems to be handling about 80%, if not more, of the traffic. We are having frequent traffic bursts during these bursts this one interface is being over saturated and traffic dropped. This has been confirmed by looking at network reports of the interfaces and when the interruption to client traffic is being reported.
The xmit-hash-policy on the bond is currently Layer2. After working with TAC and reading posts similar to this one it sounds like we need to consider changing this to Layer3+4 hash. I am not completely sure if we need to change the other side.
It seems it may not be required to set identical hash on both sides so I am hoping to get some feedback on experiences or suggestions with if we should change the settings on the Cisco Catalyst side. The Cisco Catalyst switch has a few other port channels in use and from what I can tell the port channel load balance setting is a global configuration and not per port channel setting. Not familiar enough how that may affect the other port channels, maybe it would not be a big deal.
Thanks for any additional feedback.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I always preferred to align them to L3+L4 for consistency but YMMV.
Which side you change in the first instance depends on if it's the TX or RX where you see the imbalance.
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is no requirement to align hashing algorithms for LACP bonding groups. This is strictly local logic for how the Check Point firewall is going to handle inbound and outbound traffic on the bonding group. Layer 3+4 is preferred as it is more efficient if you are looking for aggregated throughput. It won't make any difference for your switch, it will handle whatever traffic it receives on whatever port in the bonding group. But in order to achieve the best aggregated throughput it's going to be preferable to have the switch do Layer 3+4 as well, making sure you have more efficient handling of aggregated traffic on both ends.
Certifications: CCSA, CCSE, CCSM, CCSM ELITE, CCTA, CCTE, CCVS, CCME
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @Timothy_Hall ,
thanks for the info!
Do you know if modifying the Transmit Hash Policy from 'Layer2' to 'Layer3+4' on a production interface will cause any problems or issues ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Generally no, but caution is always recommended.
If it's a cluster you have the ability to execute on the standby first and failover as an option.
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Doing so will cause a queue restart on the interface, but the duration of this interface outage is very short (way less than 1 second). If I'm remembering correctly it happens so fast that ClusterXL won't even notice it. This would be the same impact as running expert mode commands ifdown ethX;ifup ethX which I sometimes use to quickly restart an interface that is having some strange issues. But like Chris said a downtime window is advised.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Timothy,
for Sync bond interface, Layer2 hashing it's better or not? Source, destination ip and port always be the same...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The default Layer 2/XOR mode for 802.3ad should be fine. Because there are only 2 IP addresses in use on the sync network and both the source and destination port number for all traffic is 8116, I doubt that setting Layer 3+4 mode will buy you anything other than increasing overhead slightly.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From ibm.com :
A single connection or TCP flow can only span one link, no matter which hash policy is used.
So the bob's suggestion about round robin it seems the only way to accomplish redundancy+load sharing, correct? Round-robin it should sequentially transimt PACKETS on available interfaces, regardless flow with same source,dst and port
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I experimented with all the available bonding modes on a bondX interface with two physicals when used as the ClusterXL sync network and it behaves as expected. With any mode other than round robin all the sync traffic only crosses one physical interface; I labbed it up here at Shadow Peak on the off-chance that somehow traffic might flow through one physical interface in one direction, yet come back over the other one in the other direction with one of the hash policy selections. But as noted above it is all considered one "flow" by the bond, so only one interface is used for the sync traffic in both directions.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I wouldn't bother with LACP. My preferred sync topology is one link to each of two switches which don't talk to each other. The links are then aggregated with round-robin transmit link selection.
One switch goes down? Both firewalls lose that member of the bond, but the other member of the bond is still up, so the bond doesn't lose link.
One firewall goes down? The other firewall doesn't lose link on any interfaces, so the bond doesn't lose link.
One interface or cable goes down? Sync traffic stops working, but this shouldn't cause a failover by itself.
This topology also expands arbitrarily in very clear ways. You want four switches? Easy, you just burn more interfaces per cluster member; no need for special multi-chassis switches or anything weird. Four cluster members? Easy, you just burn more switch ports.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good point
Never configured Round Robin, any suggestion on switch side for this type of aggregation? Any precaution?
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just don't let the switches talk to each other. They can be dumb, unmanaged Netgears or whatever, but if they talk to each other, a lot of sync traffic will end up going over the inter-switch link, making it a limit.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Changed from layer 2 (which was transmitting on only one physical link of a 4 member bond interface because source and destination mac addresses were always the same despite various source / dest IP addresses) to layer 3 and 4 and now have all 4 physical connections of bond transmitting traffic. No interruption to service during change. Great book (3rd ed) Timothy - Many thanks.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 37 | |
| 13 | |
| 11 | |
| 10 | |
| 10 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |
Upcoming Events
Tue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementTue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFTue 12 May 2026 @ 10:00 AM (CEST)
The Cloud Architects Series: Check Point Cloud Firewall delivered as a serviceThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

{kind=link}
{kind=link}
©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter