- Products
- Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- Cyprus
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
AI Security Masters E7:
How CPR Broke ChatGPT's Isolation and What It Means for You
Blueprint Architecture for Securing
The AI Factory & AI Data Center
Call For Papers
Your Expertise. Our Stage
Good, Better, Best:
Prioritizing Defenses Against Credential Abuse
Ink Dragon: A Major Nation-State Campaign
Watch HereCheckMates Go:
CheckMates Fest
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Hybrid Mesh
- :
- Firewall and Security Management
- :
- High Cpu utilization - Internet Speed drops to ver...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
High Cpu utilization - Internet Speed drops to very low level
Dear Colleagues ,
I have a problem with high CPU utilization and by the time of this issue the internet speed to go down dramatically.
Appliance Check Point 15600 - Hot fix: Check_Point_R80_30_JUMBO_HF_Bundle_T219_sk153152
I am attaching some photos from the commands executed by the time of issue.













FYI we are using Policy Based Routing & Remote Access VPN.
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
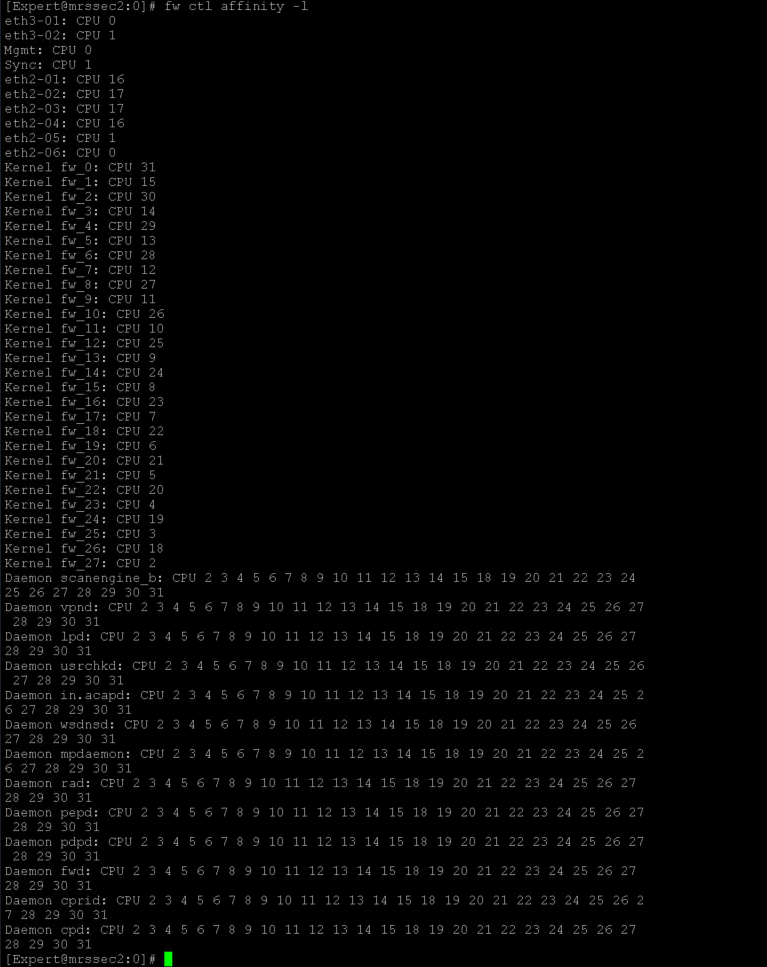
That can't be a 15600, a 15600 has 8 physical cores and 16 present with SMT enabled. Your screenshots are showing 32 cores.
It appears you have the default 4/28 split and CPUs 0/16 and 1/17 are getting killed with 46% of traffic fully accelerated, while Firewall Worker cores sit relatively idle. Likely that your interfaces are experiencing high frame loss via RX-DRP during the slow periods, which is visible with netstat -ni.
Would recommend decreasing number of firewall instances from 28 to 24 via cpconfig for a target 8/24 split. Once that is done and system rebooted, enable Multi-Queue on your 10Gbps interfaces which will require another separate reboot under Gaia kernel 2.6.18 which appears to be what you are using. Memory and disk look fine.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
25 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are you using multi queue on the interface? fw ctl affinity –l
could you show enabled_blades as well?
any messages in var/log/messages?
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Where is your traffic going in and out?
CPU0 and that is allocated to Eth3-02, Eth2-06
Based on your picture above, this CPU core goes full.
What are those interfaces used for, if its used for traffic i would activate multi Q so that you can dist the load over multiple cores.
https://sc1.checkpoint.com/documents/R80.30/WebAdminGuides/EN/CP_R80.30_PerformanceTuning_AdminGuide...
Regards,
Magnus
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That can't be a 15600, a 15600 has 8 physical cores and 16 present with SMT enabled. Your screenshots are showing 32 cores.
It appears you have the default 4/28 split and CPUs 0/16 and 1/17 are getting killed with 46% of traffic fully accelerated, while Firewall Worker cores sit relatively idle. Likely that your interfaces are experiencing high frame loss via RX-DRP during the slow periods, which is visible with netstat -ni.
Would recommend decreasing number of firewall instances from 28 to 24 via cpconfig for a target 8/24 split. Once that is done and system rebooted, enable Multi-Queue on your 10Gbps interfaces which will require another separate reboot under Gaia kernel 2.6.18 which appears to be what you are using. Memory and disk look fine.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

You refer that my interfaces are are losing packets during slow periods. What is exactly the reason for this?
These are my setting on perfomance section:

if I choose optimize for packet rate and throughput ? it recommends 6 for performance and 26 for instances.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Personally, I’d upgrade to R80.40 or R81 and enable Dynamic Workloads.
All this stuff will then be tuned automatically on the fly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
in this case reinstalling it to R80.30, 3.10 would have fixed it aswell, but well an upgrade to R80.40 may be easier 🙂
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The reason for the packet loss is insufficient CPU resources allocated to empty the 10Gbps interface ring buffers fast enough via SoftIRQ (RX-DRP), which is a responsibility of an SND/IRQ core. Based on your traffic mix and and the other information you provided, I'd recommend an 8/24 split with Multi-Queue enabled on your busy 10Gbps interfaces.
6/26 as the performance slider is showing is a general recommendation, my 8/24 recommendation is specific based on the info you provided. 6/26 might be OK too.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
+1 for Timothy Hall's recommendation.
Note also the following regarding Remote Access VPN in case the volumes are significant.
sk165853: High CPU usage on one CPU core when the number of Remote Access users is high
Indeed the number of cores consistent with that of a 15600 is shown here per:
https://www.checkpoint.com/downloads/products/15600-security-gateway-datasheet.pdf
Additionally, note only the 2.6 kernel is supported on the 15600 until R80.40.
CCSM R77/R80/ELITE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah, I wasn't accounting for the "2X" Intel Xeon E5-2630v3 (8/16 core) thought it was just 1X. Thanks for the clarification Chris.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ηello again and thank you all for your detailed answers.
I have two nodes, so when I turn the settings at first to the standby node and set the specific interfaces to multi que mode with core split to 6/26 after reboot the cluster seems that is not syncing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Correct it will not sync until both members have an identical CoreXL split. You can blunt the impact of a non-stateful failover by temporarily unchecking "Drop out of state TCP packets" on the Stateful Inspection screen of Global Properties and reinstalling policy to both members. Don't forget to recheck it when finished!
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Something that won’t happen when you use R80.40+ and dynamic workloads to manage the split, FYI.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just to be sure:
a) I turn the second node to multi que and change the core split
b) saving and reboot
c) On the first node I should change the “Drop out of state TCP packets”
d) install policy on both nodes
yes?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
a) uncheck drop out of state packets
b) publish and reinstall to both
c) change core split of second node
d) reboot it (you can't change core split and multi-queue at the same time, you must reboot after doing either one)
e) enable multi queue for relevant interface(s) on second node
f) reboot it
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tim - have another post related to this same topic which you have already commented on in regards to my VSX setup (TAC are still dragging there heels on this).
I was wondering if anyone has actually deployed R81 in a VSX setup yet and if this has any reported issues?
I'm looking to upgrade my R80.20 VSX setup to R80.40 or R81, would like to move to R81 but I think it may be a little too early for this.
Also I know the recommendation is to rebuild, but in the current climate remote upgrade is preferred method. So I will likely do an inline upgrade; from what I can tell kernel version would get upgraded, multi-queue turned on and other parameters turned on by default such are CORE load balancing parameter (SK168513).
Clearly new filesystem would not get used, but I don't see this being hugely important at the gateway side (happy to be educated on this if I'm wrong).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I personally have not worked with VSX under R81 yet, I'd suggest posting a new thread asking for community experiences where more people can see it. The resident community VSX expert (especially when it comes to performance) is @Kaspars_Zibarts.
New Book: "Max Power 2026" Coming Soon
Check Point Firewall Performance Optimization
Check Point Firewall Performance Optimization
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will do Tim.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great,
with the above steps I suppose that I won’t have any interruptions ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As the sync is not working, there will be a small dipp.
The packages will need to be reestablished.
https://www.youtube.com/c/MagnusHolmberg-NetSec
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just don't forget to check drop out of state packets at least an hour after you have changed both members and push policy again.
Regards, Maarten
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Merry Christmas to all!
I made a guide and I want to ask some final details.
A) Global Properties uncheck the drop out of state TCP Packets for blunt the impact to the failover
B) Install the policy on both cluster members
C) Change the core split of the Second Node
D) Reboot the Second Node
E) Enable multique at relevant interfaces (2nd node)
F) Reboot
After the above steps theoretical there will be no cluster so I should the reboot the active (first) node and the 2nd node with the new settings will take over?
thanx
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes that is correct, but you should check the setting of the cluster for the member that will be primary, make sure it is set to keep the active member and not return to the highest priority member.
Before rebooting the original active member first change the setting of the core assignment, then you take care of 2 things in 1 go.
Regards, Maarten
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Final Guide:
A) Global Properties uncheck the drop out of state TCP Packets for blunt the impact to the failover
B) Install the policy on both cluster members
C) Change the core split of the Second Node
D) Reboot the Second Node
E) Enable multi que at relevant interfaces (2nd node)
F) Reboot
The Second Node is ready with the new settings so we have to restart the active node and the second node
will take over.
After the reboot and when everything works appropriate we must uncheck the drop of state tcp packets and install policy to both members
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello guys,
I finalize two days ago the whole procedure with success. I am monitoring the gateway but I will be sure next week. Until Now everything seems good.
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 34 | |
| 11 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |
Upcoming Events
Tue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementTue 28 Apr 2026 @ 06:00 PM (IDT)
Under the Hood: Securing your GenAI-enabled Web Applications with Check Point WAFTue 12 May 2026 @ 10:00 AM (CEST)
The Cloud Architects Series: Check Point Cloud Firewall delivered as a serviceThu 30 Apr 2026 @ 03:00 PM (PDT)
Hillsboro, OR: Securing The AI Transformation and Exposure ManagementAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY

{kind=link}
{kind=link}
©1994-2026 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter