- Products
Quantum
Secure the Network IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloudGuard CloudMates
Secure the Cloud CNAPP Cloud Network Security CloudGuard - WAF CloudMates General Talking Cloud Podcast - Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- Bulgaria
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
Share your Cyber Security Insights
On-Stage at CPX 2025
Simplifying Zero Trust Security
with Infinity Identity!
CheckMates Toolbox Contest 2024
Make Your Submission for a Chance to WIN up to $300 Gift Card!
CheckMates Go:
What's New in R82
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Quantum
- :
- Management
- :
- Re: Problems with log latency for some gateways
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Problems with log latency for some gateways
Hello,
I have a strange issue with log-latency from some gateways.
Enviroment:
Firewall-1 Management/Log Server R81.20 running on Vmware on top of Nutanix.
Several gatways, VSX-cluster, Appliances and 3 VE-Clusters also running on Vmware/Nutanix.
Problem:
A while ago, after customer moved the Management to another Nutanix-host i noticed
that we were having log-latency (1-5 hours off) from the 3 VE-clusters and 2 Physical Appliances.
The only change that was done was to move the Management to another physical Nutanix-host.
I therefore requested a move back to the previous host and issue was solved.
Now we have the same issue again, and its the same 3 VE-clusters and 2 Physical Appliances
that are off by 1-5 hours. We do see some logs coming in so logging is not stopped completely.
From the Standby-nodes in these VE-clusters we dont have log-latency, only from the Active.
Im having a bit of an issue "proving" that its the Nutanix-solution and as far as I can see
the Management VM itself doesnt struggle. Also according to the customer they dont see anything on the Nutanix side and no other servers are experiencing issues (2-300 servers spread across multiple hosts)
Questions
* Since its the same 3 clusters Active members and 2 physical Appliances we have latency from on receiving
logs, is there some sort of internal "priority" on which logs to process/index first ?
* Any way on the Management VM-side to investigate disk-io/disk performance that might come from the ESX/Nutanix side?
Thanks!
CCSM / CCSE / CCVS / CCTE
22 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It might be that your VM has some issues with HDD access and/or CPU prioritization.
Please look here for some recommendations: https://support.checkpoint.com/results/sk/sk104848
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Val and thanks for the reply!
Do you know if any internal prioritization on which gateways to accept/index logs from?
I just find it strange that whenever this issue occurs, its the same 3 Active cluster members and 1 single physical appliance with almost no traffic that i have "lagging logs" from, while 3-4 other clusters, 6 VS`es and several other single appliances i have no latency on logs from
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is no prioritization on the management server of GW side. From what you described, this seems to be not a connectivity issue, but a management server issue related on one or multiple HW details of the VM.
I would suggest some troubleshooting steps.
1. Do your GWs log locally a lot? Check the local logs to figure it out.
2. Does your management server has a lot of waiting interrupts? How is it's CPU utilization?
3. What are the statuses of fwd processes on both sides?
4. Does your management lags on indexing logs or receiving logs? You can opel a legacy log viewer and see if the raw logs are up to date
And more. But before anything, make sure that the MGMT VM parameters are optimal. Fast storage, no CPU sharing, good RAM values.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Thanks for the reply!
The Management is running on Vmware on top of Nutanix sharing multiple hosts (and same datastores) as a few hundred other servers. When checking the Management CPU-usage from the VM-side its very low on the 4 CPU-cores, and the same on the Nutanix/Host side.
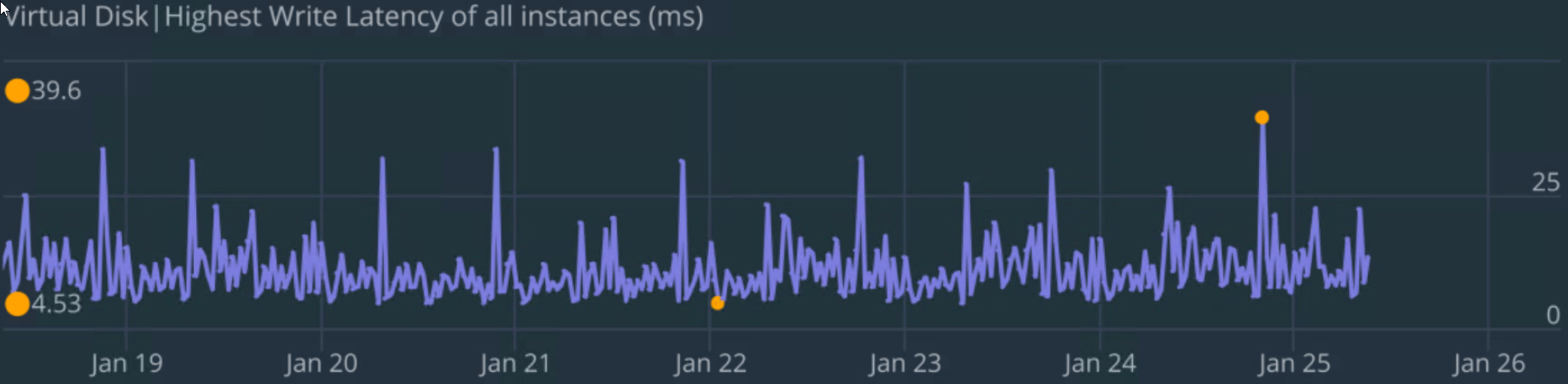
On the Nutanix/Vmware side we do however see disk-latency registered for this particular VM (see mgmt_nutanix_disk.png)
I also do see some iowait on the os-side, posted below.
What makes it even stranger is that we only see this issue from 4 Gateways (3x are Active VE cluster gateways, also running on Nutanix) and the 4th is a single Appliance with very little traffic. They are also reporting logging due to "buffer overflow".
################
[Expert@gateway:0]# cpstat fw -f log_connection
Overall Status: 0
Overall Status Description: Security Gateway is reporting logs as defined
Local Logging Mode Description: Writing logs locally due to high log rate (buffer overflow)
Local Logging Mode Status: 3
Local Logging Sending Rate: 0
Log Handling Rate: 50
Log Servers Connections
---------------------------------------------------------
|IP |Status|Status Description |Sending Rate|
---------------------------------------------------------
|X.X.X:X| 0|Log-Server Connected| 0|
---------------------------------------------------------
###############
The FW-log traffic for all these 4 gateways do have to go through 3 VS`es to reach the Management, but we dont notice any other traffic issues on these virtual systems and CPU-usage on VS/VSX is very low (below 10% in total).
[Expert@fwmngt:0]# vmstat 5 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 667904 834012 1356 21660592 0 0 3 6 2 6 5 1 92 2 0
0 0 667904 829096 1356 21664356 0 0 0 155 1238 1630 5 1 92 1 0
0 0 667904 819720 1356 21669152 0 0 0 1454 2304 3649 7 2 88 3 0
0 0 667904 817076 1356 21670992 0 0 0 120 1340 1931 6 1 91 1 0
0 0 667904 814276 1356 21674716 4 0 4 1216 1137 1529 5 1 93 2 0
[Expert@fwmngt:0]# iostat 5 5
Linux 3.10.0-1160.15.2cpx86_64 (fwmngt) 01/25/24 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.55 3.91 1.18 1.75 0.00 91.61
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 47.83 81.38 1656.65 98491441 2004959651
dm-0 31.40 65.01 1467.05 78674452 1775495012
dm-1 18.06 15.96 188.72 19311694 228393576
avg-cpu: %user %nice %system %iowait %steal %idle
1.00 4.41 1.25 1.75 0.00 91.59
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 27.40 0.00 1092.60 0 5463
dm-0 10.60 0.00 957.10 0 4785
dm-1 16.80 0.00 135.50 0 677
avg-cpu: %user %nice %system %iowait %steal %idle
3.06 3.36 1.40 1.86 0.00 90.32
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 28.00 0.80 362.70 4 1813
dm-0 6.80 0.00 56.50 0 282
dm-1 21.20 0.00 307.80 0 1539
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 2.95 1.30 1.00 0.00 93.64
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 13.40 0.00 222.70 0 1113
dm-0 0.40 0.00 118.40 0 592
dm-1 12.80 0.00 102.70 0 513
avg-cpu: %user %nice %system %iowait %steal %idle
1.00 4.81 0.85 0.90 0.00 92.44
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 13.00 0.00 156.30 0 781
dm-0 0.00 0.00 0.00 0 0
dm-1 13.00 0.00 156.30 0 781
[Expert@fwmngt:0]#
SAR
[Expert@fwmngt:0]# sar -u
Linux 3.10.0-1160.15.2cpx86_64 (fwmngt) 01/25/24 _x86_64_ ( 4 CPU)
00:00:01 CPU %user %nice %system %iowait %steal %idle
00:10:01 all 4.78 4.40 1.99 3.36 0.00 85.47
00:20:01 all 1.80 3.24 1.28 3.26 0.00 90.41
00:30:02 all 1.50 2.98 1.07 2.81 0.00 91.63
00:40:01 all 1.70 3.61 1.25 3.00 0.00 90.44
00:50:01 all 1.54 3.07 1.15 2.87 0.00 91.38
01:00:01 all 1.52 3.11 1.11 2.64 0.00 91.62
01:10:01 all 1.57 3.46 1.16 2.84 0.00 90.97
01:20:01 all 1.41 3.12 1.07 2.76 0.00 91.63
01:30:01 all 1.72 3.28 1.17 2.82 0.00 91.00
01:40:01 all 1.58 3.26 1.20 2.80 0.00 91.15
01:50:01 all 1.54 3.72 1.20 3.08 0.00 90.46
02:00:01 all 1.50 3.14 1.16 2.89 0.00 91.30
02:10:01 all 2.33 3.46 1.90 2.93 0.00 89.38
02:20:01 all 4.74 3.22 1.37 3.06 0.00 87.60
02:30:01 all 1.53 3.41 1.14 2.86 0.00 91.07
02:40:01 all 1.79 3.84 1.31 3.10 0.00 89.96
02:50:01 all 1.62 3.81 1.23 2.94 0.00 90.40
03:00:01 all 1.62 3.59 1.33 2.63 0.00 90.84
03:10:01 all 1.76 4.55 1.69 2.42 0.00 89.58
03:20:01 all 1.42 3.31 1.09 1.78 0.00 92.40
03:30:01 all 1.42 3.14 1.11 1.75 0.00 92.58
03:40:01 all 1.55 3.50 1.12 1.79 0.00 92.04
03:40:01 CPU %user %nice %system %iowait %steal %idle
03:50:01 all 1.47 3.15 1.07 1.82 0.00 92.49
04:00:01 all 1.48 3.40 1.14 1.78 0.00 92.21
04:10:01 all 1.48 3.29 1.13 1.75 0.00 92.35
04:20:01 all 1.52 3.26 1.12 1.74 0.00 92.35
04:30:01 all 1.62 3.17 1.05 1.76 0.00 92.41
04:40:01 all 1.41 2.93 0.99 1.65 0.00 93.01
04:50:01 all 1.39 2.90 0.98 1.64 0.00 93.09
05:00:01 all 1.41 3.16 1.07 1.78 0.00 92.59
05:10:01 all 1.49 3.14 1.09 1.78 0.00 92.50
05:20:01 all 1.41 3.22 1.07 1.71 0.00 92.58
05:30:01 all 1.50 3.77 1.16 1.86 0.00 91.72
05:40:01 all 1.54 3.41 1.11 1.81 0.00 92.13
05:50:01 all 1.52 3.49 1.15 1.72 0.00 92.11
06:00:01 all 1.50 3.44 1.18 1.74 0.00 92.14
06:10:01 all 1.51 4.29 1.49 2.04 0.00 90.67
06:20:01 all 1.42 3.41 1.02 1.63 0.00 92.52
06:30:01 all 1.41 3.33 1.02 1.62 0.00 92.62
06:40:01 all 1.52 3.39 1.04 1.81 0.00 92.25
06:50:01 all 1.41 3.87 1.08 1.64 0.00 92.00
07:00:01 all 1.62 3.90 1.22 1.77 0.00 91.49
07:10:02 all 1.64 3.83 1.22 2.05 0.00 91.27
07:20:01 all 1.76 4.44 1.36 1.91 0.00 90.53
07:20:01 CPU %user %nice %system %iowait %steal %idle
07:30:01 all 1.71 4.10 1.22 1.97 0.00 91.00
07:40:01 all 1.49 6.20 1.29 1.97 0.00 89.05
07:50:01 all 1.51 3.81 1.09 1.67 0.00 91.92
08:00:01 all 1.77 4.23 1.16 1.78 0.00 91.05
08:10:01 all 1.95 4.39 1.72 1.75 0.00 90.20
08:20:01 all 1.64 4.37 1.21 1.85 0.00 90.93
08:30:01 all 1.63 4.68 1.24 1.75 0.00 90.70
08:40:01 all 1.85 4.41 1.25 1.74 0.00 90.76
08:50:01 all 1.53 4.75 1.18 1.75 0.00 90.78
09:00:01 all 1.53 4.42 1.36 1.74 0.00 90.96
09:10:01 all 1.85 5.20 1.90 2.07 0.00 88.99
09:20:01 all 1.74 4.48 1.55 1.84 0.00 90.39
09:30:01 all 1.79 4.44 1.47 1.97 0.00 90.33
09:40:01 all 1.90 4.52 1.40 1.83 0.00 90.35
09:50:01 all 1.78 5.24 1.50 1.83 0.00 89.66
10:00:01 all 1.81 4.97 1.48 1.90 0.00 89.83
10:10:01 all 1.87 5.13 1.62 2.23 0.00 89.15
10:20:01 all 1.76 4.51 1.35 1.87 0.00 90.50
10:30:01 all 1.99 4.41 1.23 1.76 0.00 90.61
10:40:01 all 1.62 4.04 1.19 1.71 0.00 91.44
10:50:01 all 1.47 3.96 1.14 1.70 0.00 91.74
Average: all 1.71 3.83 1.25 2.12 0.00 91.09
[Expert@fwmngt:0]#
CCSM / CCSE / CCVS / CCTE
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see what Val is saying...that definitely could be the issue.
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Just wanted to give this case an update as the problem now is automagically solved without any changes being done on Nutanix.
After moving a VLAN from 1 bond interface to another last week, the VS went "down" on the secondary VSX-member where it was standby.. On the Active member it complained about missing CCP-packets for this VLAN as the cause, on the VSX-member it went down on it complained about missing CCP-packets on a vswitch/wrp-interface that no changes had been made to. We could clearly see CCP-packets so network was not an issue.
Few days later we were having massive latency-issues for all traffic through this VS (that we dont think is related, but never know) but the lack of redundancy issue made it hard to investigate further.. In addition to loads of Fast Accel-rules last night, a week after the CCP-issue started we also added two more cores to this VS and suddently the CCP-issue was also gone.
Today also the log latency issue is gone..
I must say, VSX R81.20 is not good for my mental or physical health, has been a more or less nightmare for the last few months since we upgraded. A few good weeks after T41 solved the constant VS-failover issue we had in T26 until we moved a VLAN 🙂
Not looking forward to moving the next 20+ VLANS, if its a requirement to add a core when you move a VLAN we`ll run out of cores pretty fast :D. I do have a TAC case for the issue, hoping there will be a root cause found.
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Man, I am glad it works, BUT, I am not glad hearing about this taking toll on you, thats not good 😞
My mentality is always, whats the point of all the money in this world if you cant enjoy it? Health comes first BEFORE anything, cause put it this way, if you lose your health (God forbid), billions of $s wont make a slight difference.
Always put yourself first my friend, that way, others will see the difference too.
Anyway, sorry, did not mean to sound like Dr Phil now lol
Best,
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, much appreciated! 🙂
Its always hard to ignore such issues when you are in the middle of them, and "caused" them after a change you made.
The noise from hundreds of users/management and packet-loss in national critical infrastructure for days/weeks is not my idea of fun anymore 😄
After 20+ years as a consultant there have been quite a few such events not just with Check Point, but after R81.20 i really dont feel safe making any changes, weird issues seems to pop up everywhere and unfortunately getting hold of someone at TAC that doesnt ask for the same information for weeks is getting harder every year.
Thats not just CheckPoint but a general issue with all vendors i work with that seems to just get worse, its just that i spend 80% of my day with CheckPoint products 🙂
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I totally get what you are saying. I found it managable to deal with things like that in my 20s, but now, 20 years later, not so much lol
Best,
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
VSX R81.20 has once again provide itself a great release..
The issus we had the last time was VS Down on Standby-node (and also _alot_ of latency issues that im not sure if are related).
This issue happened when moving VLAN 117 from "bond1" to "bond20" and this became the lowest VLAN ID and monitoring-VLAN.
Had a TAC-case for a while until the issue solved itself by adding two more CPU-cores to the VS.
TAC then said they found no issues on the Firewall/Config and that the issues were related to performance..
Today i was tasked with moving 17 more VLAN`s the same way.
Started with a high VLAN-ID which was moved with no issues. Then moved the lowest VLAN ID 102 and now we have the exact same situation again.. In addition the VS popped over to the DR-site and is down at the HQ, causing an abruption to the network for a few secs aswell. Probably related to ARP 😄.
Since VLAN 102 worked both before and after the VS decided to pop over to the DR-site we know for a fact that this VLAN is defined on all switcches.
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
O man, issues never stop, right? How did you make out with the latest problem?
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Status-updates, with various customer contact persons, calling local Check Point Office to get attention . You know, just a regular day in this business 😄
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just got an update from TAC pointing to sk121337 which do match the issue and also as part of adding an additional core the last time a restart was made. Will make it a PITA if we have to restart the VS` es every time we move a VLAN. We have two bonds so have to calculcate if "bond1" or "bond20" will get a lower VLAN ID with every change if this keeps happening.
Also find it a bit strange that documentation and the "legend" of "cphaprob -m if" says that the lowest VLAN ID will be monitored why i have loads of VLAN in the 100x series on bond1, even VLAN2, while VLAN 2504 is the monitoring VLAN selected on bond1". May potentially be due to the current "Down" situation on the VS. dont see this on other VS`es and it was definately bond1.2 earlier 🙂
##############
ClusterXL VLAN monitoring per interface:
Interface | VS ID | Monitored VLANs
-----------------+--------------+-------------------
bond1 | 2 | 2504
-----------------+--------------+-------------------
bond20 | 2 | 102
-----------------+--------------+-------------------
VSX load sharing: Lowest VLAN is monitored per interface on each VS.
When a VS is connected to a VSW with the same physical interface and a lower VLA N,The wrp leading to VSW is considered as the lowest VLAN for the physical inter face.
##############
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ouch, yea, says install policy and run cpstop; cpstart??!! Wow, to me, that does not sound right at all...I mean, Im NOT vsx expert, neither I claim to ever have been one, but Im certain there has to be better way to do this.
Have you double checked with TAC on it?
Best,
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The cpstop/cpstart sk was reccommended by TAC. I do suspect (hope) it will solve the issue but if we are to have maintenance windows every time we move a VLAN that is, or will become the lowest on a interface im just as impressed with Check Point at the moment as the customer is. Unfortunately the customer is fairly large and protects national critical infrastructure so this happening again will land me a few more meetings with the customers incident manager/department, really looking forward to that part again aswell 😄
At this moment its a more passive-aggressive feeling towards spending more time with this product 😄
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Its good you are not upset about it, because I guarantee you lots of people would be. Funny story, one year when I was in New Zealand and I was having dinner at a nice restaurant and waitress brought me totally wrong meal and when I told her, she was so sorry and apologizing and said "O, Im so sorry, it was my fault, I will understand if you are upset and yelling" and I just laughed and said "Well, if yelling will help, sure, I can do that" lol
Anyway, my mentality in life no matter what the situation is this...its not what happens to you, its how you deal with it. I think thats true no matter what.
Best,
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just got a new update from TAC that now also includes rebooting when we need to move VLANS:
############
After further research and confirmation from my TL, the problem stems, as you know, from the monitored vlans.
What I suggest, you can disable VLAN monitoring temporarily. move the VLANs, and reboot.
Step 1
#:fw ctl set int fwha_monitor_all_vlan 0
#:cpstop;cpstart
Step 2
Move VLANs
Step 3
reboot (modifications do not survive the reboot)
############
Although I do understand that this is a workaround for a VLAN monitoring bug/issue, moving VLAN`s and networks/adding interfaces is something that is done on a more or less weekly basis in this enviroment with loads of migrations and projects requiring new networks.
Whats next, having to reboot every time we have to make a rulebase change ? 😄
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
K, on a very serious note now...does your local SE know about this case? I assume they do, but if not, I would definitely talk to them about it, because they should be able to see if they can escalate it further internally.
To me, I truly believe there must be a better way to solve this, rather than doing cpstop and cpstart any time there is a change done. As you said, whats next, having to reboot when there is policy change??
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi!
Yes, local CP AM is already on the issue and escalating further in TAC. Havent updated them about this great solution yet, want to make sure that a restart of the VS works first, in the maintenance window i just got alloccated tonight 😄
This is definately not an acceptable permanent solution for the customer. (or me)
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I hope that gets somewhere...man, though I dont know you, I can tell you are a trooper, as they say, you seem to be really patient about all this, which Im sure most people would throw in the towel, as saying goes...
Andy
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Really hope so. The kernel parameter TAC tells us to set to 0 and reboot is a parameter already set to 0 on VSX VSLS R81.20 and not even in use. VSX VSLS according to doccumentation monitors lowest VLAN ID only. So not only is the recccomendation on this "permanent - moving vlan issue" solution totally unacceptable, it also seems to be technically wrong 🙂
Thanks for your kind words! Can never give up when a customer have issues, but I do seriously consider getting a career where i dont have to work with this product anymore, atleast not "in the field". Its just not worth the headache
CCSM / CCSE / CCVS / CCTE
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Health ALWAYS first my friend, always. Yes, I agree 100%, to me, that also sounds totally unacceptable AND wrong. I mean, even if you knew nothing about the firewalls, logically thinking about it, I would not see whole lot of sense to it, but thats just me.
Best,
Andy
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 7 | |
| 6 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 2 | |
| 2 |
Upcoming Events
Tue 12 Nov 2024 @ 03:00 PM (AEDT)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (APAC)Tue 12 Nov 2024 @ 10:00 AM (CET)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (EMEA)Tue 12 Nov 2024 @ 02:00 PM (CET)
Part 1: Harnessing AI to Prevent Cyber Attacks and Enhance Defense - EMEATue 12 Nov 2024 @ 11:00 AM (EST)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (AMERICAS)Tue 12 Nov 2024 @ 02:00 PM (EST)
Part 1: Harnessing AI to Prevent Cyber Attacks and Enhance Defense - AmericasTue 12 Nov 2024 @ 03:00 PM (AEDT)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (APAC)Tue 12 Nov 2024 @ 10:00 AM (CET)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (EMEA)Tue 12 Nov 2024 @ 02:00 PM (CET)
Part 1: Harnessing AI to Prevent Cyber Attacks and Enhance Defense - EMEATue 12 Nov 2024 @ 11:00 AM (EST)
No Suits, No Ties: From Calm to Chaos: the sudden impact of ransomware and its effects (AMERICAS)Tue 12 Nov 2024 @ 02:00 PM (EST)
Part 1: Harnessing AI to Prevent Cyber Attacks and Enhance Defense - AmericasWed 20 Nov 2024 @ 05:00 PM (CET)
Under the Hood: DO NOT Renew your WAF without watching THIS!!Tue 19 Nov 2024 @ 12:00 PM (MST)
Salt Lake City: Infinity External Risk Management and Harmony SaaSWed 20 Nov 2024 @ 02:00 PM (MST)
Denver South: Infinity External Risk Management and Harmony SaaSThu 21 Nov 2024 @ 02:00 PM (MST)
Denver North: Infinity External Risk Management and Harmony SaaSTue 03 Dec 2024 @ 10:00 AM (GMT)
UK Community CNAPP Training Day 1: Cloud Risk Management WorkshopAbout CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2024 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
About Us
UserCenter