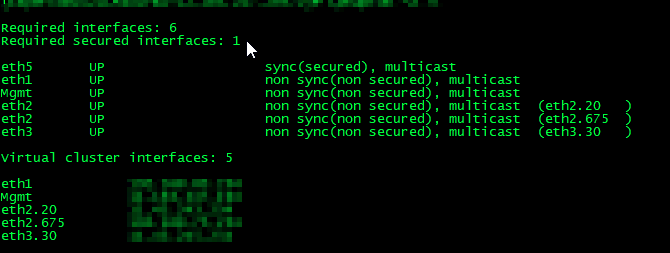
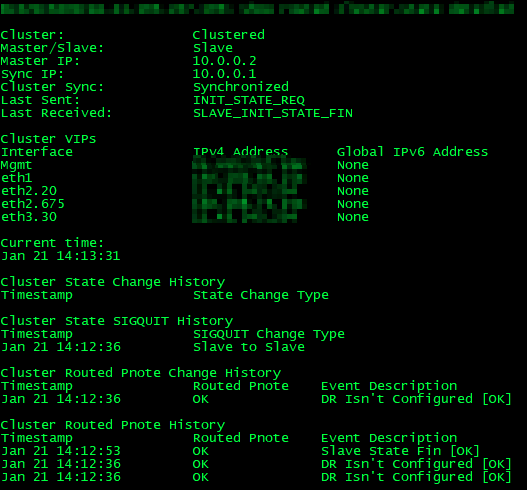
Are you *sure* that ClusterXL is not logging anything about the cluster right around when the outage starts? Use a log filter of "type:Control" to zero in on ClusterXL-related messages; also try looking in /var/log/messages*. Any CUL (Cluster Under Load) notifications? It is not common for a Check Point firewall with the latest GA Jumbo HFA to partially fail in such a way that it cannot pass traffic without a failover occurring, as ClusterXL has its monitoring talons sunk pretty deep into the firewall code. VRRP on the other hand is another matter entirely (split-brain and routing black hole cocktails anyone?), but I digress...
If ClusterXL/messages file is not uttering a peep until you cause a manual failover, that usually suggests some kind of Layer 2 or Layer 3 issue is occurring such as Proxy ARP not working any more, duplicate IP/MAC address, a routing flap, or maybe even a switch STP issue. You can sort of confirm this by setting up monitoring of upstream and downstream IP address in ClusterXL here to cause a failover to occur: sk35780: How to configure $FWDIR/bin/clusterXL_monitor_ips script to run automatically on Gaia / Sec...
Could also be some kind of transient resource issue on the firewall but that is unlikely, you can check out this possibility by running cpview in historical mode (-t) and stepping back to the point in time right before the outage started. Unfortunately the only way to really figure this out is to get on the console of the active firewall when the outage is happening, and look at traffic trying to enter and leave the firewall interfaces with tcpdump (assuming there is any).
--
CheckMates Break Out Sessions Speaker
CPX 2019 Las Vegas & Vienna - Tuesday@13:30
Gaia 4.18 (R82) Immersion Tips, Tricks, & Best Practices Video Course
Now Available at https://shadowpeak.com/gaia4-18-immersion-course