Let me start by saying that false positives do exist. On the other hand, a url from one category can change in a few clicks... That is why Checkpoint is adding URL reputation, IP reputation, DNS reputation and others to the threat intelligence. Additionally, sites that are normally allowed to all users i.e News/Media is often infected with crypto miners.This is the new trend. Simply because the bad guys knows that those sites are visited by large number of people.
A url is based on URL categorisation and at the same time a URL is simply an application. A web application.
For your questions:
1) As mentioned above any url is an application as well. When it will get more popularity and analysed further it will get a name and more detailed descriptions and fined tuned policies.
2) If you check the logs, it is not block by the URL filtering but from the category as High Risk. If you block High risk categories, this is the reason regardless if you allow that URL category.
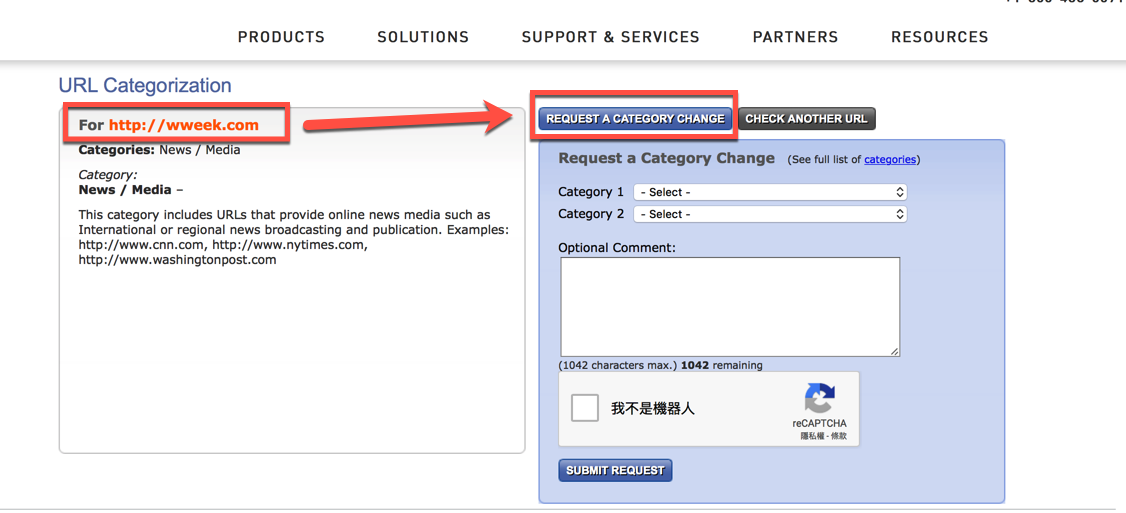
3) There is a number of reasons why a news/media site can be categorised as High Risk. The first is false positive, the second is that through Threat Intelligence was found to contain something malicious. The third is that links inside that URL connects to malicious activities.
4) No, mix http/https does not imply high risk.
End users do not understand (and care) the technical complexities of why a URL is blocked. They just want to view the site, and most often a site that they visit from their home.
Is up to your organisation policy to evaluate and exclude the different URLs so a definite answer does not exist.
Thanks,
Charris Lappas