Всем доброго дня, предлагаю вашему вниманию мою статью опубликованную в прошлом году в журнале "Системный Администратор" (как блог пост не могу создать - не разрешена такая опция поэтому как дискуссию) .
За 10 лет ежедневной работы с МСЭ Checkpoint мне довелось увидеть немало неисправностей. Разные версии, топологии, но что оставалось неизменным, так это неисправности вследствие ошибок самих администраторов. В этой статье я расскажу о самых часто совершаемых ошибках и как их избежать.
Удаление объекта который используется.
Особенно характерно для сисадминов пришедших из мира MS Windows и привыкших подтверждать все сообщения системы на уровне предупреждения (“Warning”). Из всех ошибок эта пожалуй может оказаться самой губительной для вашей карьеры. Checkpoint позволяет удалить объект который используется, часто даже предупредив о последствиях удаления. К сожалению не все и не всегда читают\понимают эти предупреждения. Моя рекомендация – получив сообщение о том что объект используется, ни в коем случае не удалять его, а пройти по всем указанным в сообщении местам и удалить оттуда этот объект пользуясь здравым смыслом конечно. А теперь пример из жизни. Попал ко мне однажды клиент с жалобой на безумно медленный интернет во всей организации – веб страницы открываются с трудом, почта посылается\принимается с задержкой в пол-часа. После нескольких проверок стало ясно что их Checkpoint грузит линию в интернет на все 100%, при чем происходит это и при полностью отключенной внутренней сетью.
Логи в SmartView Tracker показывали необычно большое количество соединений SSH на различные адреса в интернете. Посмотрев через SSH на содержание директорий МСЭ обнаружил файлы с именами bruter.sh, uploader.sh и так далее, а также файлы больших размеров с именами фильмов на то время идущих в кинотеатрах. Стало ясно что МСЭ клиента взломали и используют как хранилище вареза и сканнер SSH хостов в интернете. Посмотрев логи SmartView Tracker Audit (в новых версиях называется Management) стало понятно что произошло. Было себе такое правило в Security Policy пока не пришел в ИТ новый человек и в один прекрасный день решил сделать ‘чистку’. Вот это правило:

Vova_PC – хост во внутренней сети
Corporate-gw, Management – соответственно сам МСЭ и его SmartCenter.
Так вот, наткнувшись на объект Vova_PC решил он
удалить его так как это было имя его предшественника уже покинувшего компанию. Нажал на ‘Delete’ получил предупреждение:
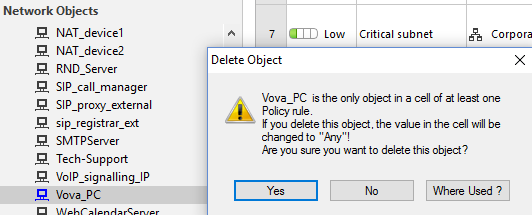
Проигнорировал его, нажал на ‘Yes’ и установил политику безопасности (Security Policy) на МСЭ. Тем самым превратив вышеупомянутое правило в:

Другими словами открыл доступ к МСЭ отовсюду. Для полного счастья ползователем SSH с правами root был admin с паролем qwe123. Судя по логам взломали их Checkpoint меньше чем за час после изменения с IP в Румынии. Им можно сказать «повезло» так как взломщики не поняли куда попали и не продолжили дальше внутрь сети, просто использовали МСЭ как сервер Линукс.
Использование Dynamic Object в политике безопасности для блокирования доступа на веб сайты.
Ошибка которая гарантировано перегрузит\завалит ваш МСЭ. Всегда происходит в такой ситуации – администратор МСЭ получает задание блокировать доступ к ресурсу в интернете у которого нет постоянного IP. Checkpoint конечно умеет это делать, но… в соответствующем модуле – URL Filtering/App Control требующий своей лицензии. Лицензия = деньги. Но что делать если нет денег? Админ продолжает искать в SmartDashBoard пока не находит Dynamic Object – как ему кажется, то что искал:
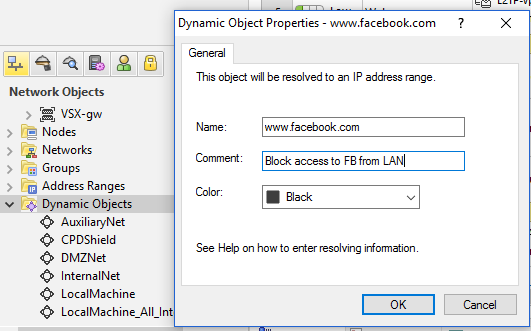
Админ создает его, конфигурирует согласно просьбе, создает правило в политике безопасности, устанавливает политику на МСЭ… и как правило вся организация теряет интернет а админ доступ к МСЭ. Причина тому нагрузка на процессор 100%, так как этот обьект должен быть определен и на CLI а не только в SmartDashboard, то он остается неопределенным и его использование в правилах с большим траффиком приводит к такому результату.
Не проверять наличие свободного места на жёстком диске
Первое что я делаю если есть проблема и надо делать дебаг – проверяю наличие места на жёстком диске. Самое смешное что проблемы с местом на диске могут выражаться в совершенно казалось бы несвязанных поломках:
- Невозможно установить политику безопасности а получаем ошибку типа “Could not install policy, error 0x36748956 …”
- Невозможно открыть логи в SmartView Tracker, или открывается но получаем пустой лог.
- Невозможно обновить IPS/URL Filtering/App Control – и опять же, выдает ошибку которая ничего не говорит администратору
- Невозможно подсоединиться к SmartCenter в SmartDashboard
- Я могу продолжать и продолжать ...
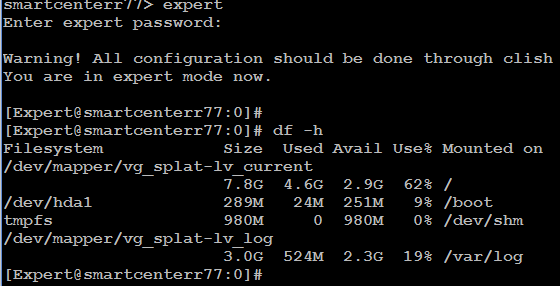
Тут надо помнить что Check Point хоть и МСЭ но также и сервер Линукс основанный на RHEL. Как любому серверу ему требуется свободное место на диске для исправной работы – для загрузки файлов обновлений из интернета, для обработки и консолидации логов, для шифрования/дешифрования файлов, для обработки внутренних баз данных которые в большинстве своем файлы на диске. Поэтому наличие достаточного свободного места критично, по своему опыту скажу что не стоит опускаться меньше 1 гига особенно в разделе “/” где установлена сама ОС. Проверить наличие места можно командой df -h в expert mode:
Использование простых паролей легких для взлома.
Это настолько элементарно что вы можете не поверить встречается ли это в жизни — легкие пароли да еще и пароли МСЭ? Неприятно удивлю что не только встречается но и очень часто.
Обычно это начинается с интегратора который устанавливает или обновляет версию существующего МСЭ и как всегда спешит на еще 2-3 установки в тот день в других местах.
И так как есть необходимость использовать пароль администратора много раз во время установки и первичной конфигурации то многие облегчают себе работу тем, что выбирают легкие для введения пароля, такие как qwe123/1q2w3e/123456 сказав себе — “нет проблем. Как закончу поменяю на более тяжелые”, и конечно забывают сделать это. Я видел МСЭ которые установили 10 лет назад еще в версии R55 с таким легким паролем и 10 лет после этого обновляли и обновляли не меняя пароль так как боялись потерять доступ к нему или трогать то что работает.
Как я рассказывал выше такие пароли могут легко привести к взлому самого МСЭ.
Поэтому моя рекомендация тут во-первых изменить при установке нового МСЭ пользователя admin на другое имя — не бойтесь, ничего плохого не произойдет, или если пользователь уже существует и боитесь его удалить — просто поменяйте его пароль на что-то длинное и очень сложное, сохраните этот пароль в программе или в месте где вы храните все свои остальные пароли, и больше никогда им не пользуетесь для входа в систему, а вместо этого создайте каждому администратору свой индивидуальный пользовательских аккаунт.
Забыть отключить акселерацию (SecureXL) перед началом дебага.
Это распространенная ошибка которая случалась и у меня и у техподдержки самого Чекпоинта. Когда со всех сторон давят на нас решить эту проблему как можно скорее естественна такая ошибка. Когда-то это не было настолько важно но сегодня 90% МСЭ используют компонент акселерации называемый на языке Checkpoint SecureXL. Этот компонент позволяет сократить время обработки проходящих через МСЭ пакетов тем что рассматривается и проверяется процессором только первый пакет сессии. Если говорим о TCP то в снифере fw monitor мы увидим только TCP SYN. Поэтому первое что надо сделать до начала какого-либо дебага в современных МСЭ это проверить включен ли этот компонент акселерации и если да то отключить его временно, и включить после окончания дебага.
Кстати обратите внимание что сделать это можно двумя способами: через cpconfig — не делайте этого так как это отменяет акселерацию на постоянной основе и вдобавок просит сделать рестарт всему МСЭ.
А сделать это можно весьма просто с командной строки следующим образом:
проверить включена ли акселерация:
fwaccel stat
если включена временно отключить:
fwaccel off
по окончании дебага включаем обратно:
fwaccel on
Пометка: отключение акселерации естественно увеличит нагрузку на процессор МСЭ поэтому стоит проверить до того что процессор не перегружен и если да, то уменьшить эту нагрузку до включения дебага.
Не пользоваться «страховкой» против ошибок конфигурации — Database Revision Control.
С самого своего начала Checkpoint дает возможность сохранить конфигурацию для резервного копирования включая все объекты и политику безопасности. Можно сделать копию в любой момент по желанию или установить автоматическое сохранение перед каждой установкой политики безопасности. К моему удивлению не более 10 -15% МСЭ которые я видел используют эту функцию. И зря, это спасает ситуацию при случайном удалении объекта или правила или в случае возникновения проблем в сети, когда не ясно какое изменение в МСЭ привело к этому.
Сам процесс восстановление прост до банальности — несколько кликов и все вернулось к прежнему состоянию. Единственным недостатком можно назвать использование места на диске этими копиями, но даже тут можно установить сколько копий хранить. Активируем функцию резервных копий Database Revision Control так:
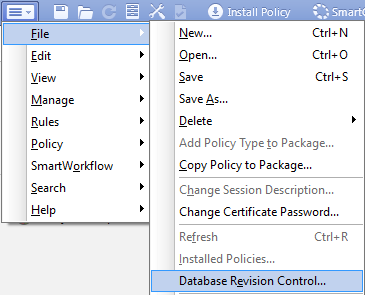
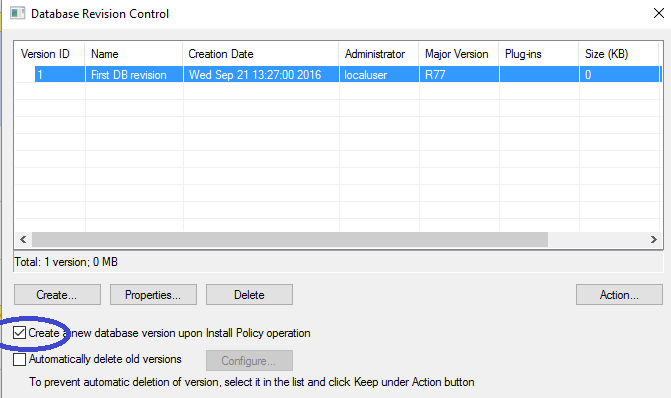
Для восстановления конфигурации нажмите Action -> Restore Version…
Использовать Reject вместо Drop в правилах политики безопасности.
Происходит если не понимают разницу. Все просто — reject не только блокирует пакеты, но и посылает инициатору уведомление об этом. В случае TCP это TCP Reset — это не только добавляет нагрузку на МСЭ, но и сообщает второй стороне что их собственно заблокировал МСЭ. Не вижу никакой причины использовать Reject.

Перезапуск всего МСЭ когда требуется перезапуск только SmartCenter .
Часто администраторы забывают что программное обеспечение фильтрующего модуля МСЭ и программное обеспечение управления SmartCenter — это 2 самостоятельных компонента, даже когда они установлены на одном сервере. Поэтому когда по какой-либо причине хотят перезагрузить SmartCenter делают это перезагрузкой всего сервера. Проблему это может и решит, но и весь файервол перегрузит. Намного проще перегрузить только сервис SmartCenter командами в expert mode:
Закрыть сервис:
cpwd_admin stop -name FWM -path "$FWDIR/bin/fw" -command " fw kill fwm”
Загрузить его снова:
cpwd_admin start -name FWM -path "$FWDIR/bin/fwm" -command "fwm”
Не синхронизировать время МСЭ через ntp.
Не раз мне приходилось участвовать в изнуряющем дебаге чтобы позже понять что время МСЭ и соответственно его логов ошибочное. МСЭ создает много логов — политики безопасности, всех его сервисов (логи с расширением .elg) и это очень помогает в дебаге и анализе происшествий. Все логи создаваемые МСЭ имеют дату и время.
Когда часы сервера на котором установлен МСЭ отклоняются от точного времени — это делает логи ненадежными и даже вводящими в заблуждение. Из моего опыта могу с уверенностью утверждать — не важно насколько продвинутый и дорогой сервер, его часы будут отклоняться со временем. И не только это — отклонение оно нелинейное. То есть если я вижу что сегодня часы отстают на 15 минут, невозможно сказать на сколько они отставали неделю или месяц назад. Были случаи когда из-за этой неизвестной неточности логи становились бесполезными. Решение — синхронизируйте МСЭ с внутренним или внешним сервером NTP. Возможно конфигурация 2 серверов NTP — одного главного, и одного вторичного. Сделать это можно или в Gaia GUI или на командной строке:
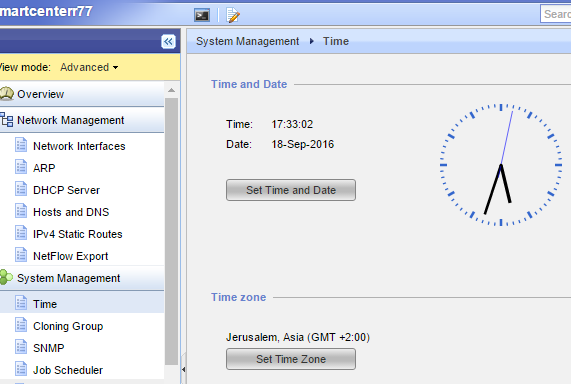
smartcenterR77> set ntp server primary 13.13.13.1 version 2 smartcenterR77> set ntp server secondary 23.23.23.1 version 2 smartcenterR77> save config
Не проверять резервные копии конфигурации на работоспособность.
Checkpoint имеет несколько способов сохранить конфигурацию — через GUI, на командной строке, сделать одноразово или автоматически. Важнее всего конечно SmartCenter содержащий все объекты политики безопасности и аккаунты пользователей. Конфигурацию модуля тоже стоит сохранять но не так критично, в нем интересует только адреса и таблица маршрутизации. Часто SmartCenter установлен на VmWare или другой инфраструктуре виртуализации. Тогда легче — просто периодически делать Snapshot. Но если бэкап делается средствами самого Checkpoint или своими скриптами, то обязательна проверка работоспособности этих копий. То есть делать в лабораторных условиях полное восстановление МСЭ из резервной копий конфигурации.
Опять говорю из личного опыта.
Обратился к нам как-то клиент с проблемой Smartcenter — не поднимается с ошибками диска. Не страшно, на этом SmartCenter раз в неделю запускался бэкап который по завершению Checkpoint кидал по FTP на внутренний сервер. Клиент с его интегратором установили новый сервер, инсталлировали МСЭ без конфигурации и начали пробовать восстановить из backup саму конфигурацию. Кинули upgrade import один файл бэкапа — ошибка, файл повреждён не может быть открыт. Второй файл — тоже самое, третий файл… в общем они перебрали более 20 файлов бэкапа и все оказались повреждены. В итоге он был вынужден пригласить специалистов которые восстановили данные SmartCenter напрямую с железа проблематичного диска.Так что если вы делаете бэкап средствами Checkpoint или любой другой автоматизированной системой, включая собственные скрипты, всегда проверяйте свой бэкап. Нужно не забывать что Checkpoint это сервер Линукс и чтобы сделать бэкап как любой другой сервер он собирает важные файлы, сжимает и архивирует их и сохраняет на внешнем носителе или сервере. И тут много шансов чему-то пойти не так — в папке /tmp не было достаточно места для работы tar/gzip, принимающей сервер FTP повредил файлы при получении и так далее.
Спасибо за внимание.
https://www.linkedin.com/in/yurislobodyanyuk/
