- Products
Quantum
Secure the Network IoT Protect Maestro Management OpenTelemetry/Skyline Remote Access VPN SD-WAN Security Gateways SmartMove Smart-1 Cloud SMB Gateways (Spark) Threat PreventionCloudGuard CloudMates
Secure the Cloud CNAPP Cloud Network Security CloudGuard - WAF CloudMates General Talking Cloud Podcast - Learn
- Local User Groups
- Partners
- More

This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
- Products
- Quantum (Secure the Network)
- CloudGuard CloudMates
- Harmony (Secure Users and Access)
- Infinity Core Services (Collaborative Security Operations & Services)
- Developers
- Check Point Trivia
- CheckMates Toolbox
- General Topics
- Infinity Portal
- Products Announcements
- Threat Prevention Blog
- CheckMates for Startups
- Learn
- Local User Groups
- Upcoming Events
- Americas
- EMEA
- Czech Republic and Slovakia
- Denmark
- Netherlands
- Germany
- Sweden
- United Kingdom and Ireland
- France
- Spain
- Norway
- Ukraine
- Baltics and Finland
- Greece
- Portugal
- Austria
- Kazakhstan and CIS
- Switzerland
- Romania
- Turkey
- Belarus
- Belgium & Luxembourg
- Russia
- Poland
- Georgia
- DACH - Germany, Austria and Switzerland
- Iberia
- Africa
- Adriatics Region
- Eastern Africa
- Israel
- Nordics
- Middle East and Africa
- Balkans
- Italy
- APAC
- Partners
- More
- ABOUT CHECKMATES & FAQ
- Sign In
- Leaderboard
- Events
May the 4th (+4)
Roadmap Session and Use Cases for
Cloud Security, SASE, and Email Security
SASE Masters:
Deploying Harmony SASE for a 6,000-Strong Workforce
in a Single Weekend
Paradigm Shifts: Adventures Unleashed!
Capture Your Adventure for a Chance to WIN!
Mastering Compliance
Unveiling the power of Compliance Blade
CPX 2024 Content
is Here!
Harmony SaaS
The most advanced prevention
for SaaS-based threats
CheckMates Go:
CPX 2024 Recap
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- CheckMates
- :
- Products
- :
- Quantum
- :
- Management
- :
- Connections dropped during Connectivity Upgrade
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Are you a member of CheckMates?
×
Sign in with your Check Point UserCenter/PartnerMap account to access more great content and get a chance to win some Apple AirPods! If you don't have an account, create one now for free!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jump to solution
Connections dropped during Connectivity Upgrade
Hello,
I am upgrading our firewalls from R77.30 to R80.10. We have 17 ClusterXL clusters in high availability mode. Each cluster has two members running the GAIA OS on VMWare. I’m attempting to use the connectivity upgrade method to minimise disruption. To create enough space to copy the installation file “Check_Point_R80.10_T421_Fresh_Install_and_Upgrade_from_R7X.tgz” onto the firewall and import it I have had to:
- expand the hard drive size (in VMWare vSphere)
- expand the /dev/sda3 partition,
- resize the physical volume,
- then use lvm_manager to expand the lv_log volume
During these steps you need to reboot the firewall a number of times. This is fine when upgrading the standby cluster member. Then after that I use the cphacu commands to failover to the newly upgraded cluster member. So far so good and no disruption to the network. Then when I expand the hard drive size etc on the former active member and reboot it, it becomes the active member again. This is a hard failover and any open connections are dropped. You need to reboot 3 times and each time we failover over to the upgraded member and back causing disruption on the network.
Running cphaprob stat on the upgraded member shows that it is in the ready state because “another member was detected with a lower fw version.” Running cphaprob stat on the non-upgraded member only shows the local firewall and it is in the active state.
How can I perform the upgrades without dropping any connections? I.e. once we have failed over to the upgraded member, I want it to stay the active member until the other firewall is upgraded, surviving reboots of the other firewall.
1 Solution
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I got a couple of suggestions from R&D on how to resolve this:
1. Do all the necessary disk resizing prior to upgrading the cluster to R80.10 (while cluster is still using R77.30) and before you use the cphacu command. This does cost an extra failover and is the recommended solution.
2. If you can't have the extra failover, you can "trick" the older version into thinking it has a newer version as follows:
- Add in fwkern.conf on the non-upgraded member: fwha_version=3500 (FYI the "official" number for R80.10 is 3120)
- Run cphacu
- After rebooting the upgraded member, R77.30 will think it has a higher version and will be in Ready state (thus won't fail back)
- Before upgrading the other R77.30 member, remove the fwha_version line from fwkern.conf.
19 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
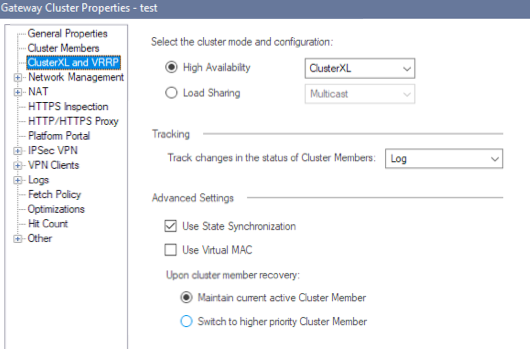
There's a setting in the Gateway Cluster Properties that controls this.
Make sure "Maintain current active Cluster Member" is enabled prior to doing an upgrade.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Dameon, I saw that setting there, however I thought that a cluster member having a lower software version would override this setting?
There are cluster members with a lower software version on this subnet / VLAN
[member with higher software version will go into state 'Ready'].
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't believe that is necessarily the case here.
That said, this point is not something mentioned in the Best Practices guide for a Connectivity Upgrade: Best Practices - Connectivity Upgrade (CU)
Speaking of which, there's a step listed there that talks about changing the version of the cluster before proceeding to upgrade the primary, specifically pushing the policy only to the secondary member.
Did you do that step?
I believe that's relevant to solving the problem as the "policy ID" is encoded in the CCP packets (see the ATRG): ATRG: ClusterXL
When you do this step only on the secondary member, the policy ID will be different, which should cause the original primary to back off until it gets back in sync.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK thanks I'll give it a shot with the 'Maintain current active Cluster Member' setting enabled and report back on how it goes.
I did change the cluster version and push it out to the cluster. As per the instructions the installation succeeded on the upgraded member and failed on the non-upgraded member.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So I tried out using the "Maintain current active Cluster Member" setting , however the same problem as described in my original post occurs. After upgrading fw2 and failing over to it using the cphacu commands, then rebooting the non-upgraded firewall(fw1) the status of the firewalls is:
On the upgraded firewall
fw2> cphaprob stat
Cluster Mode: High Availability (Active Up) with IGMP Membership
Number Unique Address Assigned Load State
1 n.n.n.17 0% ClusterXL Inactive or Machine is Down
2 (local) n.n.n.18 0% Ready
Ready state reason: another member was detected with a lower FW version.
On the non-upgraded firewall
fw1> cphaprob stat
Cluster Mode: High Availability (Active Up) with IGMP Membership
Number Unique Address Assigned Load State
1 (local) n.n.n.17 100% Active
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I got a couple of suggestions from R&D on how to resolve this:
1. Do all the necessary disk resizing prior to upgrading the cluster to R80.10 (while cluster is still using R77.30) and before you use the cphacu command. This does cost an extra failover and is the recommended solution.
2. If you can't have the extra failover, you can "trick" the older version into thinking it has a newer version as follows:
- Add in fwkern.conf on the non-upgraded member: fwha_version=3500 (FYI the "official" number for R80.10 is 3120)
- Run cphacu
- After rebooting the upgraded member, R77.30 will think it has a higher version and will be in Ready state (thus won't fail back)
- Before upgrading the other R77.30 member, remove the fwha_version line from fwkern.conf.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cool trick , thx
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great Thanks Dameon, wish I had thought of option 1 myself.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
CDT ![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please provide a link that describes it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
sk111158:
Introduction
The Central Deployment Tool (CDT) is a utility that runs on an R77 / R77.X / R80 / R80.10 Security Management Server / Multi-Domain Security Management Server (running Gaia OS).
It allows the administrator to automatically install CPUSE Offline packages (Hotfixes, Jumbo Hotfix Accumulators (Bundles), Upgrade to a Minor Version, Upgrade to a Major Version) on multiple managed Security Gateways and Cluster Members at the same time.
Cluster upgrades are performed automatically according to the sk107042 - ClusterXL upgrade methods and paths.
The CDT uses CPUSE Agents on the remote managed Security Gateways and Cluster Members to perform package installation. The CDT monitors and manages the entire process.
The CU use fwha_version kernel parameter part of the process.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All
It is my first post and sorry if it is a silly question but just wanted to know if checkpoint has a solution yet to this problem? As in the secondary firewall once it has been upgraded it will remain as Primary/Active while we are working on original Primary (irrespective of the number or times the primary reboots) .
I am planning an upgrade this weekend with 1 SMS and two GW ClusterXL (HA)(77.30 to 80.20) and was reading the guide about best practice with CU and in Step 17 page 18 it only says that one will be active and other will be standby, but does that mean it could be Original Primary becomes primary ? What If I want to control that and only failback once the Primary (original primary) is completely ready?
Help is appreciated.
Thank you in advance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@PP26 I think, terminology is a bit off here.
We are talking Active | Standby | Ready when doing GW clustering. During cluster upgrade, the first cluster member you lift to R80.20 will be in Ready or Standby state depending on CU parameters. When the "old" cluster member is turned off, the new one becomes Active.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @_Val_ apologize for the confusion. So let me try again to hopefully ask my question a bit better .
Lets use Primary FW = A and Backup = B
So I lifted B to R80.20 first and then I turn off new member as per
https://dl3.checkpoint.com/paid/7b/7b22658ee3d35d95632c544190065733/CP_Cluster_ConnectivityUpgrade_B... (Page15-17)
Step 8/9/10/13 (11 and 12 excluded since only 2 member in my cluster).
Now when I come to start upgrading FW A let's say 2 scenarios
scenario A
I have to increase the volume or lets say update CPUSE or something else due to which I need to reboot it before actually upgrading to 88.20. So when this comes back up will it take the role or being Active ? As per the original persons post seems like since this is lower version it will take it ? yeah ?
Scenario B
If I only have to do one reboot and that would be for 88.20 upgrade, then as soon as it comes online , will it automatically take the role of being Active and kick out FW B from being Active? Or will it wait until in the above link we complete step 16 (page 18) when we Install the Access Control Policy ? As in the document it says in step 17 the one will be active it does not say which one will be active .
Basically I am trying here to control that FW A does not become active until I see the upgrade has properly completely and then I make FW A as active by restarting CP service on FW B.
I hope I am able to explain this well. Sorry about the confusion 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you reboot R77.30 member before upgrading, it will resume Active state after booting. To avoid issues, you may want to disconnect it from production networks.
When both members are on R80.x, the actual cluster roles both cluster members assume are controlled on the cluster object. It can be that current active remains or it always fall back to the higher priority member.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @_Val_
Once again thanks a lot for helping out. On you response about
"If you reboot R77.30 member before upgrading, it will resume Active state after booting. To avoid issues, you may want to disconnect it from production networks" << I believe you mean once my backup has be upgraded to 80.20 and now if before rebooting Primary which is still on 77.30 if I reboot it . Correct?
I am going to do this work remotely and hence if I remove it from network even I will not be able to access it . Can you suggest a way to overcome this so that I can still be able to access it ? I though about shut down all interfaces except for just the mgmt interface , will that work ? or will mgmt interface being up can cause the 77.30 member to still come back up after reboot and resume its Active state ?
Also I saw in this post (few response above) some suggestions where we can change some fwkernel value on member which is on 77.30 to make it look like it is on higher version so that when it reboots it will think/believe it is on maybe 80.30 while the actual Active would be on 80.20 so after reboot it will not take Active state?
Sorry for too many questions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@PP26 No issues should arise if you follow upgrade guide line by line
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
HI @_Val_ but the guide does not talk about multiple reboot and what happens in that scenario, hence my confusion.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
👍
Leaderboard
Epsum factorial non deposit quid pro quo hic escorol.
| User | Count |
|---|---|
| 6 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |
Upcoming Events
Thu 25 Apr 2024 @ 11:00 AM (CEST)
CheckMates in Russian - Возможности и риски искусственного интеллектаThu 25 Apr 2024 @ 11:00 AM (CEST)
CheckMates in Russian - Возможности и риски искусственного интеллектаThu 02 May 2024 @ 10:00 AM (CEST)
CheckMates Live BeLux: How Can Check Point AI Copilot Assist You?About CheckMates
Learn Check Point
Advanced Learning
YOU DESERVE THE BEST SECURITY
©1994-2024 Check Point Software Technologies Ltd. All rights reserved.
Copyright
Privacy Policy
Facts at a Glance
User Center